Настройка провайдеров
Подключение нескольких LLM-провайдеров с настройкой параллелизма, очередей, прокси, заголовков и аутентификацией.
Подключение нескольких провайдеров
Подключите несколько провайдеров одновременно — Meridian умеет переключаться между ними по префиксу модели. Пример ниже подключает OpenAI, Anthropic и self-hosted vLLM.
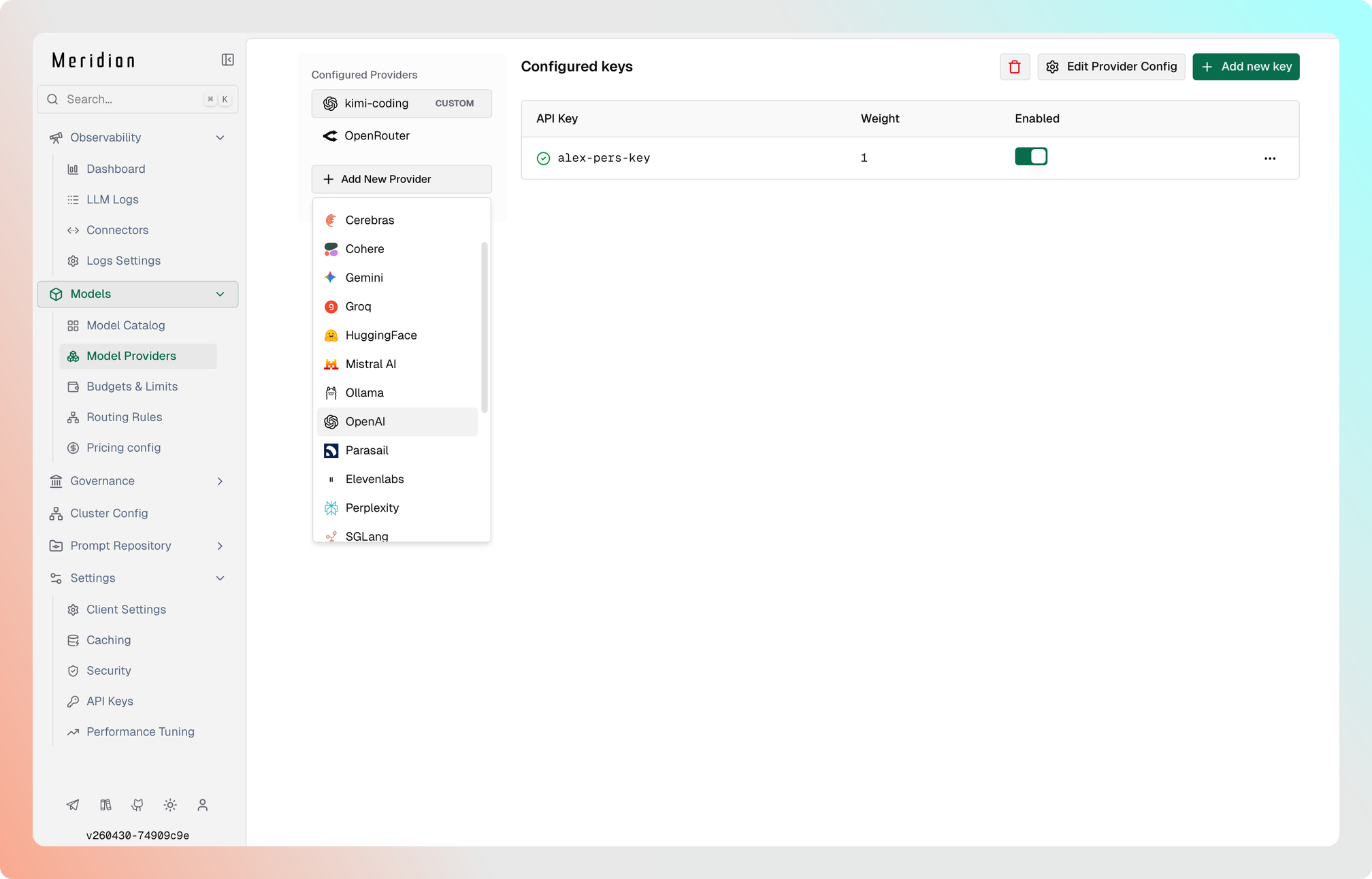
- Откройте
http://localhost:8080. - В боковой панели выберите Model Providers.
- Выберите провайдера и заполните ключи доступа.
# Добавление OpenAI
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
]
}'
# Добавление Anthropic
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "anthropic",
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
]
}'
# Добавление vLLM (self-hosted OpenAI-совместимый сервер)
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "vllm-local",
"keys": [
{
"name": "vllm-key-1",
"value": "dummy",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"base_url": "http://vllm-endpoint:8000",
"default_request_timeout_in_seconds": 60
},
"custom_provider_config": {
"base_provider_type": "openai",
"allowed_requests": {
"chat_completion": true,
"chat_completion_stream": true
}
}
}'Имя ключа (name) внутри одного провайдера должно быть уникальным.
{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
]
},
"anthropic": {
"keys": [
{
"name": "anthropic-key",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
]
},
"vllm-local": {
"keys": [
{
"name": "vllm-key",
"value": "dummy",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"base_url": "http://vllm-endpoint:8000",
"default_request_timeout_in_seconds": 60
},
"custom_provider_config": {
"base_provider_type": "openai",
"allowed_requests": {
"chat_completion": true,
"chat_completion_stream": true
}
}
}
}
}Kubernetes DNS (для произвольного эндпоинта). При запуске в Kubernetes используйте полные доменные имена (FQDN), например http://<service>.<namespace>.svc.cluster.local:8000, для cross-namespace эндпоинтов. Короткие имена http://<service>:8000 работают только в пределах одного namespace.
Закрытые контуры и self-signed сертификаты. Если ваш собственный провайдер использует HTTPS с self-signed или внутренним CA, добавьте "insecure_skip_verify": true или "ca_cert_pem": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----" в network_config.
Выполнение запросов
Когда провайдеры подключены, Meridian принимает запросы в любом из них через единый endpoint /v1/chat/completions. Префикс модели определяет провайдера:
curl --location 'http://localhost:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "openai/gpt-4o-mini",
"messages": [
{"role": "user", "content": "Hello!"}
]
}'Meridian автоматически приводит запрос к API нужного провайдера и возвращает ответ в OpenAI-совместимом формате.
Переменные окружения
Подготовьте переменные окружения для ключей доступа провайдеров. Meridian понимает как прямые значения, так и ссылки на переменные через префикс env.:
export OPENAI_API_KEY="your-openai-api-key"
export ANTHROPIC_API_KEY="your-anthropic-api-key"
export MISTRAL_API_KEY="your-mistral-api-key"
export CEREBRAS_API_KEY="your-cerebras-api-key"
export GROQ_API_KEY="your-groq-api-key"
export COHERE_API_KEY="your-cohere-api-key"Правила обработки переменных окружения:
"value": "env.VARIABLE_NAME"— ссылка на переменную окружения."value": "sk-proj-xxxxxxxxx"— прямое значение ключа.- В ответах GET-эндпоинтов и в панели управления чувствительные данные автоматически маскируются.
Расширенная настройка
Взвешенная балансировка
Распределяйте трафик между несколькими ключами или провайдерами по весам. Пример ниже делит запросы 70/30 между двумя ключами OpenAI — удобно для управления rate limits или расходом по разным аккаунтам.
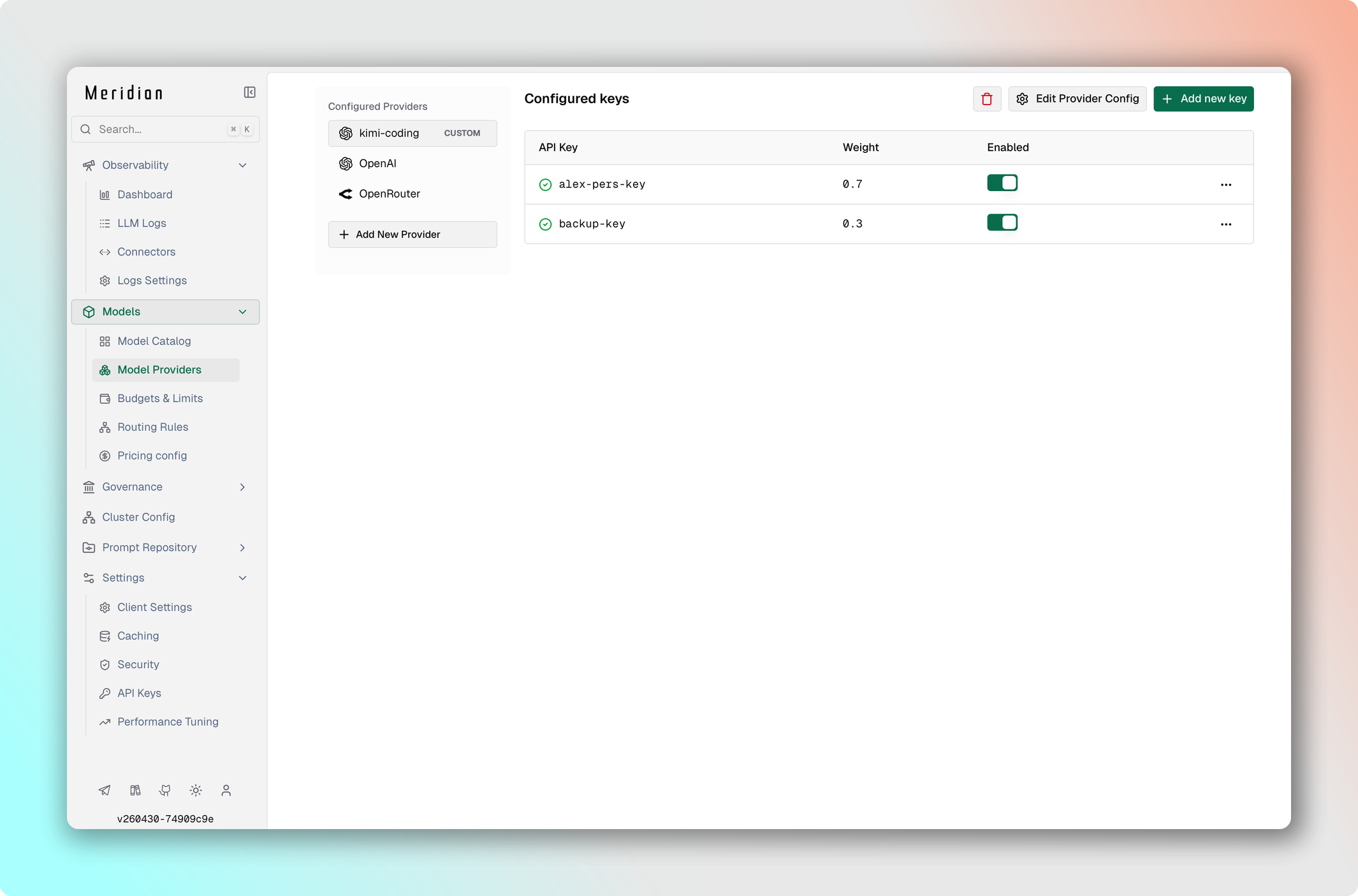
- Перейдите в Model Providers → Выбреите провайдера.
- Нажмите Add Key, чтобы добавить второй ключ.
- Установите веса (
0.7и0.3). - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY_1",
"models": ["*"],
"weight": 0.7
},
{
"name": "openai-key-2",
"value": "env.OPENAI_API_KEY_2",
"models": ["*"],
"weight": 0.3
}
]
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY_1",
"models": ["*"],
"weight": 0.7
},
{
"name": "openai-key-2",
"value": "env.OPENAI_API_KEY_2",
"models": ["*"],
"weight": 0.3
}
]
}
}
}Ключи под конкретные модели
Используйте разные ключи для разных моделей — это удобно для разделения биллинга и контроля доступа. Пример: премиум-ключ для reasoning-моделей (o1-preview, o1-mini) и стандартный ключ для остальных GPT.
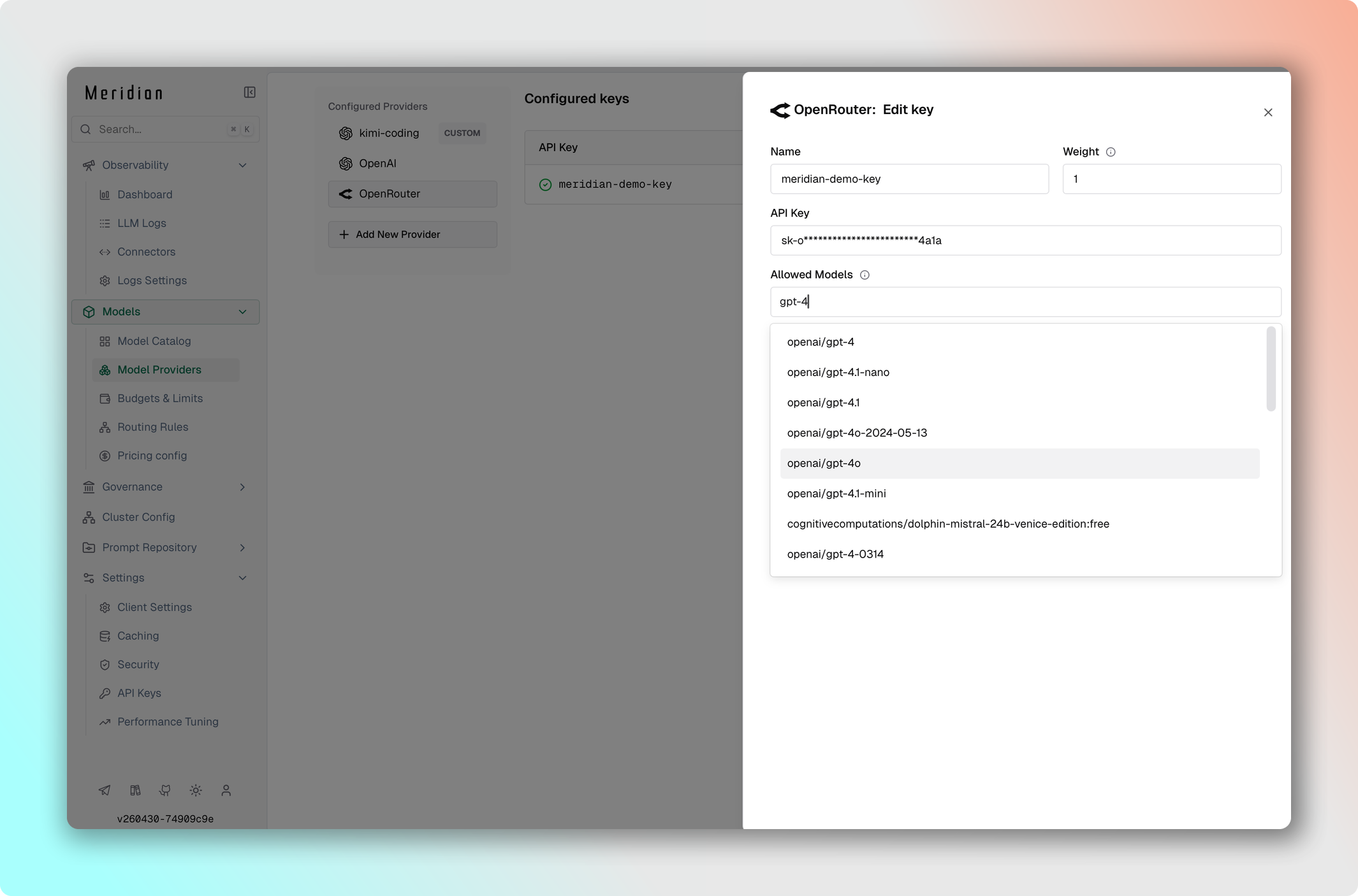
- Перейдите в Model Providers → Выберите провайдер.
- Добавьте первый ключ с моделями
["gpt-4o", "gpt-4o-mini"]. - Добавьте премиум-ключ с моделями
["o1-preview", "o1-mini"]. - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0
},
{
"name": "openai-key-2",
"value": "env.OPENAI_API_KEY_PREMIUM",
"models": ["o1-preview", "o1-mini"],
"weight": 1.0
}
]
}'{
"providers": {
"openai": {
"keys": [
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["gpt-4o", "gpt-4o-mini"],
{
"weight": 1.0
},
{
"name": "openai-key-2",
"value": "env.OPENAI_API_KEY_PREMIUM",
"models": ["o1-preview", "o1-mini"],
"weight": 1.0
}
]
}
}
}Произвольный Base URL
Переопределите endpoint провайдера — пригодится для self-hosted моделей, локальных серверов разработки или OpenAI-совместимых бэкендов (vLLM, Ollama, LiteLLM).
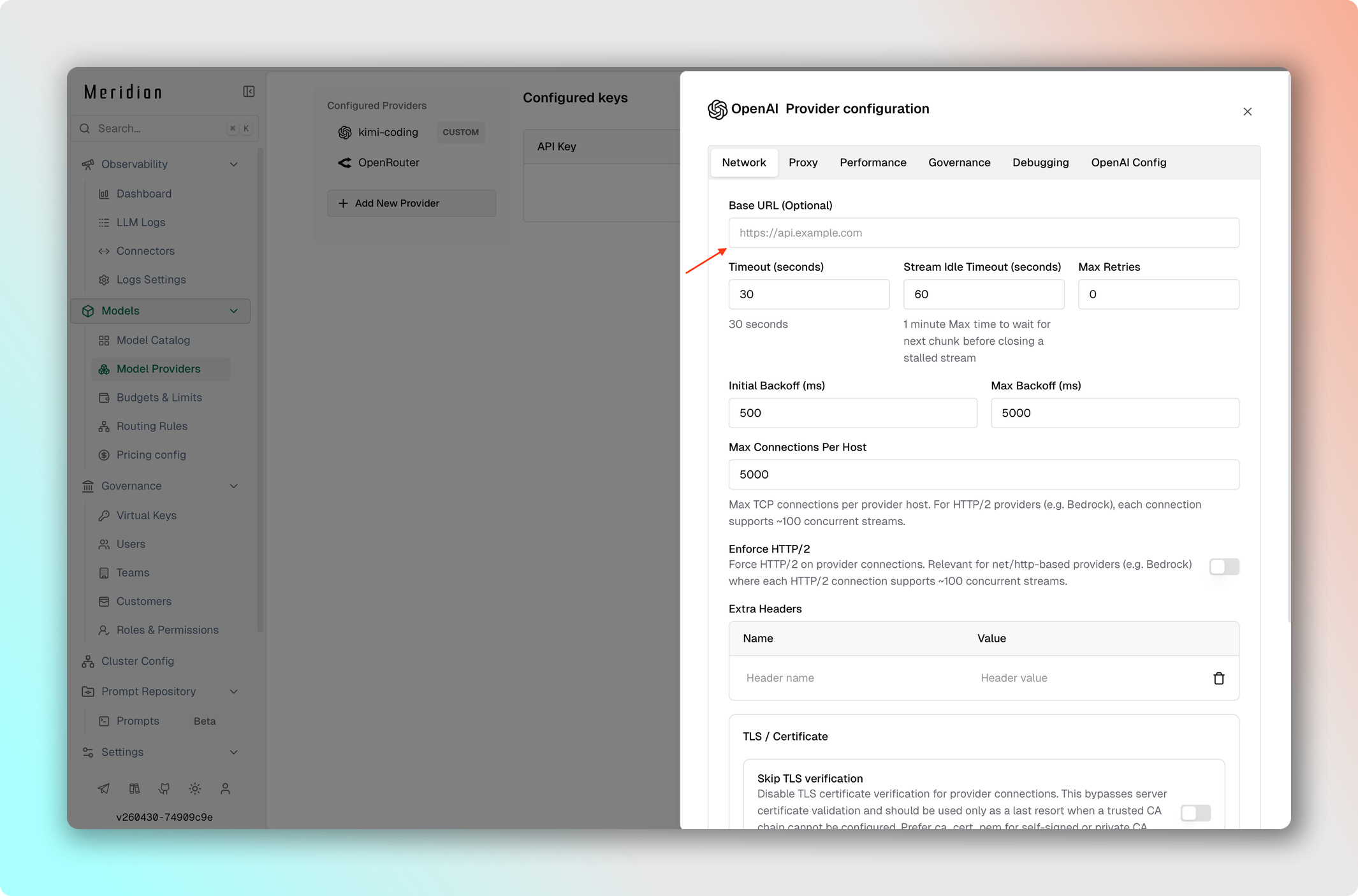
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Network config.
- Установите Base URL:
http://localhost:8000/v1. - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"base_url": "http://localhost:8000/v1"
}
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"base_url": "http://localhost:8000/v1"
}
}
}
}Для self-hosted провайдеров (Ollama, SGL) base_url обязателен. Для стандартных провайдеров — опционален и переопределяет endpoint по умолчанию.
Управление повторами
Настройте поведение при временных сбоях и rate limits. Пример настраивает экспоненциальный backoff с пятью повторами, начальной задержкой 1 мс и потолком 10 секунд — оптимально для нестабильных сетевых маршрутов.
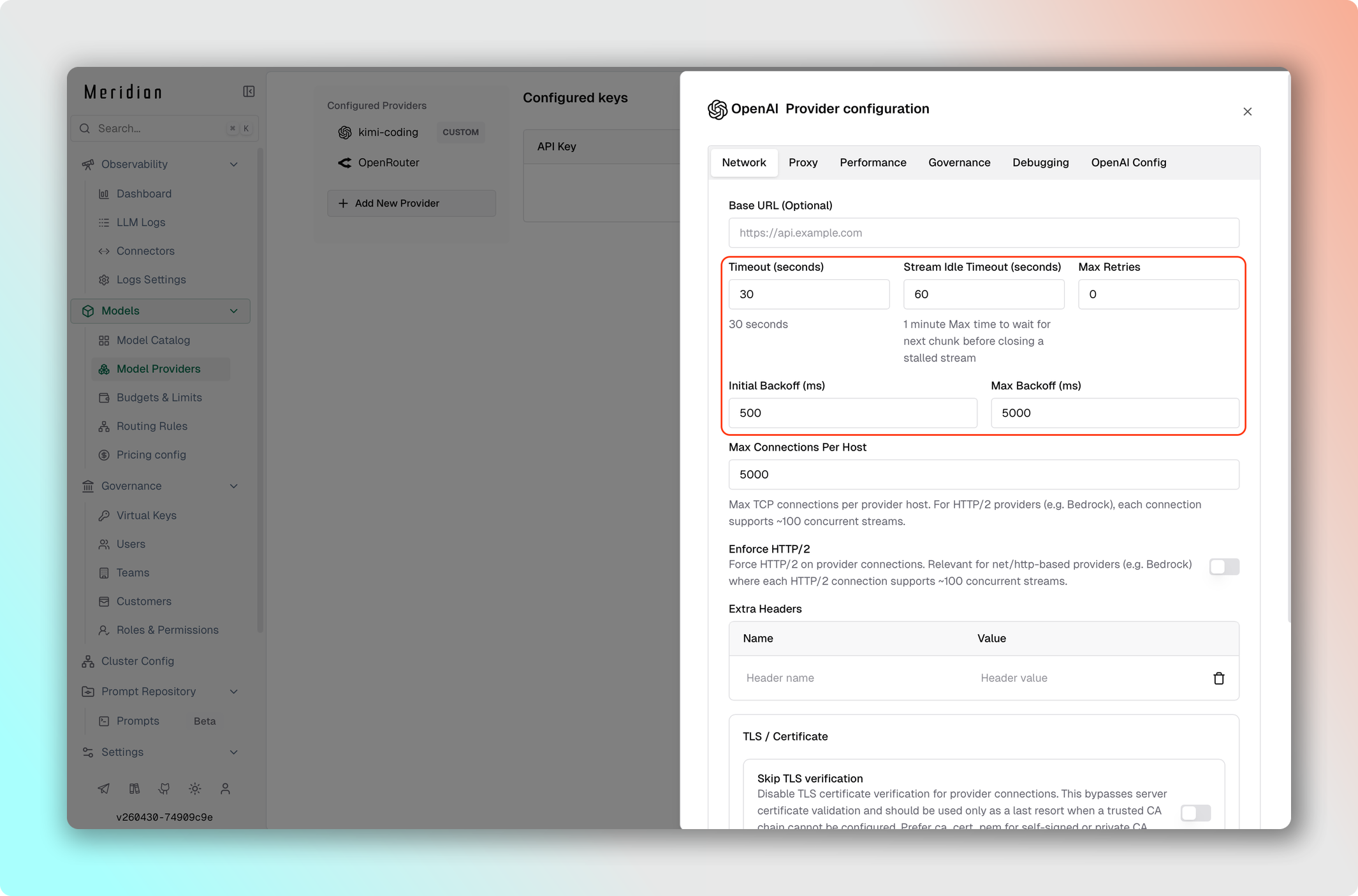
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Network config.
- Установите Max Retries:
5. - Установите Initial Backoff:
1мс. - Установите Max Backoff:
10000мс. - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"max_retries": 5,
"retry_backoff_initial_ms": 1,
"retry_backoff_max_ms": 10000
}
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"max_retries": 5,
"retry_backoff_initial_ms": 1,
"retry_backoff_max_ms": 10000
}
}
}
}Параллелизм и размер очереди
Настройте производительность под каждого провайдера: число воркеров и размер очереди (по умолчанию — 1000 воркеров и 5000 элементов очереди). В примере OpenAI получает высокую пропускную способность (100 воркеров, очередь 500), а Anthropic — консервативные значения, чтобы не упираться в его rate limits.
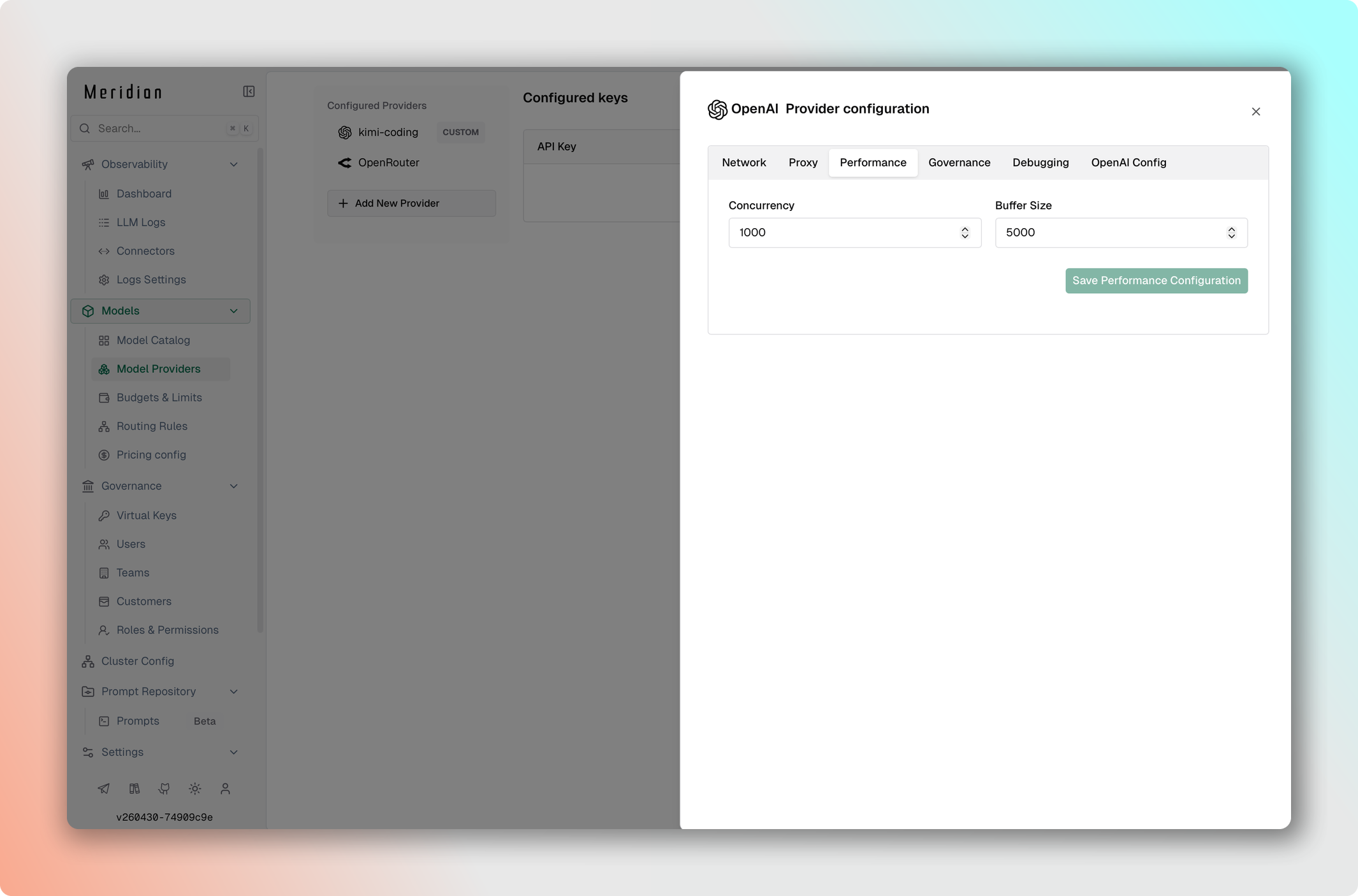
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Performance tuning.
- Установите Concurrency: число воркеров (100 для OpenAI, 25 для Anthropic).
- Установите Buffer Size: размер очереди (500 для OpenAI, 100 для Anthropic).
- Сохраните изменения.
# OpenAI с высокой пропускной способностью
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"concurrency_and_buffer_size": {
"concurrency": 100,
"buffer_size": 500
}
}'
# Anthropic с консервативными лимитами
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "anthropic",
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"concurrency_and_buffer_size": {
"concurrency": 25,
"buffer_size": 100
}
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"concurrency_and_buffer_size": {
"concurrency": 100,
"buffer_size": 500
}
},
"anthropic": {
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"concurrency_and_buffer_size": {
"concurrency": 25,
"buffer_size": 100
}
}
}
}Произвольные заголовки
Meridian поддерживает два способа добавить произвольные заголовки в запросы к провайдерам: статические на уровне провайдера и динамические на уровне отдельного запроса.
Статические заголовки (уровень провайдера)
Заголовки, которые автоматически добавляются ко всем запросам данного провайдера. Используется для требований конкретного провайдера, версионирования API или организационных метаданных.
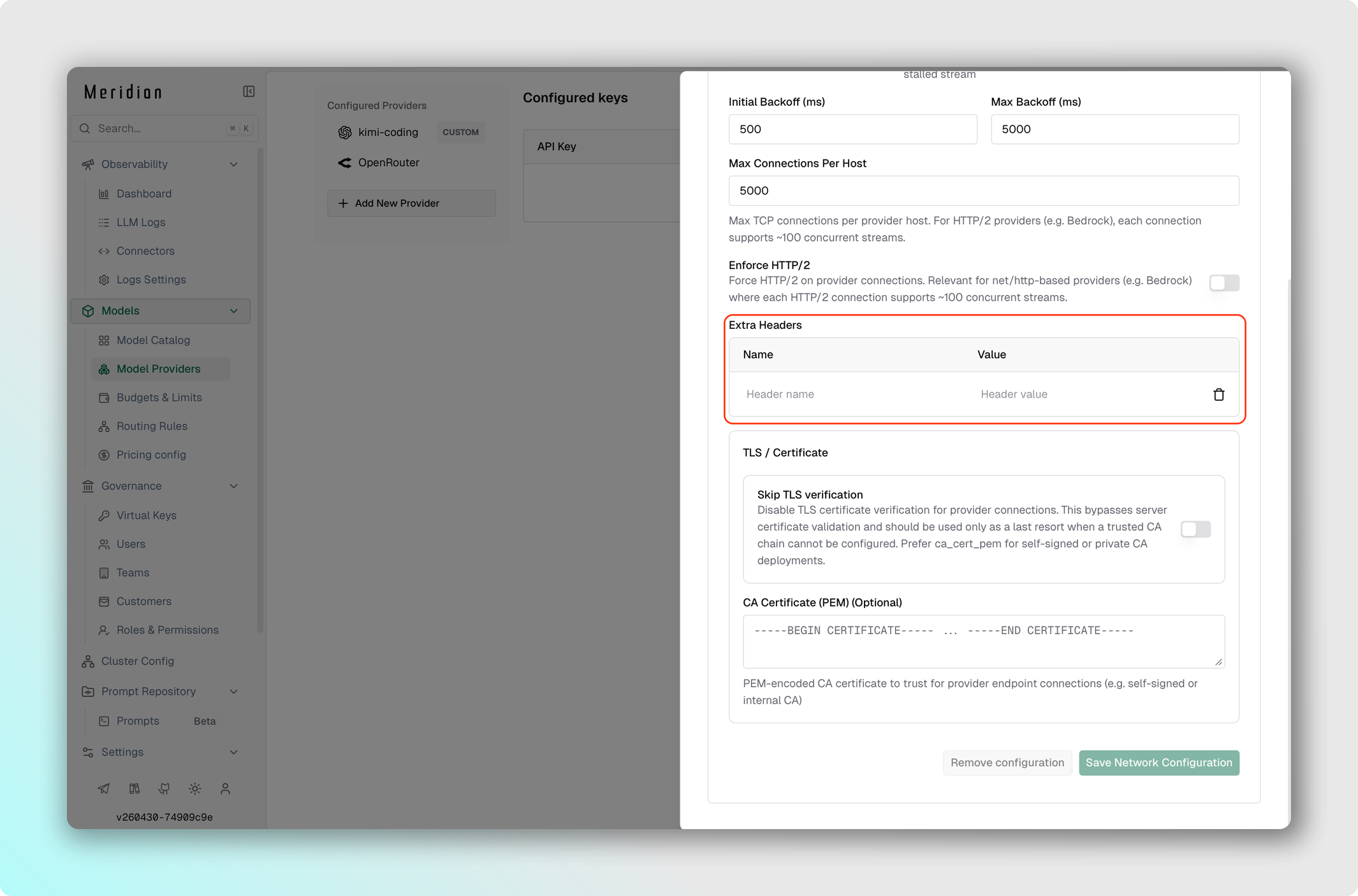
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Network config.
- Добавьте заголовки в секции Extra Headers.
- Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"extra_headers": {
"x-custom-org": "my-organization",
"x-environment": "production"
}
}
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"extra_headers": {
"x-custom-org": "my-organization",
"x-environment": "production"
}
}
}
}
}Динамические заголовки (на запрос)
Передавайте произвольные заголовки в каждом конкретном запросе через префикс x-bf-eh-*. Префикс снимается перед отправкой к провайдеру. Используется для метаданных запроса, идентификации пользователя или произвольных трейс-меток.
curl --location 'http://localhost:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'x-bf-eh-user-id: user-123' \
--header 'x-bf-eh-tracking-id: trace-456' \
--data '{
"model": "openai/gpt-4o-mini",
"messages": [
{"role": "user", "content": "Hello!"}
]
}'Префикс x-bf-eh- снимается перед отправкой, поэтому x-bf-eh-user-id уходит к провайдеру как user-id.
Примеры использования:
- идентификация:
x-bf-eh-user-id,x-bf-eh-tenant-id; - трейсинг:
x-bf-eh-correlation-id,x-bf-eh-trace-id; - метаданные:
x-bf-eh-department,x-bf-eh-cost-center; - A/B-тестирование:
x-bf-eh-experiment-id,x-bf-eh-variant.
Denylist заголовков
Meridian ведёт denylist — заголовки, которые никогда не передаются провайдеру, независимо от настроек:
denylist := map[string]bool{
"proxy-authorization": true,
"cookie": true,
"host": true,
"content-length": true,
"connection": true,
"transfer-encoding": true,
// запрет подмены аутентификации через x-bf-eh-*
"x-api-key": true,
"x-goog-api-key": true,
"x-bf-api-key": true,
"x-bf-vk": true,
}Denylist применяется и к статическим, и к динамическим заголовкам, чтобы исключить класс уязвимостей с подменой аутентификации.
Переопределение beta-заголовков
Для провайдеров на основе Anthropic (Anthropic, Vertex, Bedrock, Azure) Meridian ведёт встроенную матрицу поддержки заголовков anthropic-beta. Эти значения по умолчанию можно переопределить на уровне провайдера, если поддержка у апстрима меняется быстрее, чем Meridian обновляет встроенные defaults.
- Перейдите в Model Providers → Configurations → выберите провайдера → Beta Headers.
- Каждый известный beta-заголовок отображается со встроенным статусом поддержки.
- Используйте dropdown Override:
Enabled,DisabledилиDefault(использовать встроенное значение). - Сохраните изменения.
curl --location --request PUT 'http://localhost:8080/api/providers/vertex' \
--header 'Content-Type: application/json' \
--data '{
"network_config": {
"beta_header_overrides": {
"redact-thinking-": true,
"fast-mode-": false
}
}
}'{
"providers": {
"vertex": {
"network_config": {
"beta_header_overrides": {
"redact-thinking-": true,
"fast-mode-": false
}
}
}
}
}Ключи переопределения — это префиксы заголовков (например, "redact-thinking-"), а не полные значения. Это сохраняет работу переопределений при появлении новых date-versioned заголовков.
Прокси
Маршрутизируйте запросы через прокси для compliance, безопасности или географических требований. Пример: HTTP-прокси для OpenAI и SOCKS5 с аутентификацией для Anthropic — типичный сценарий корпоративных сетей и регионального доступа.
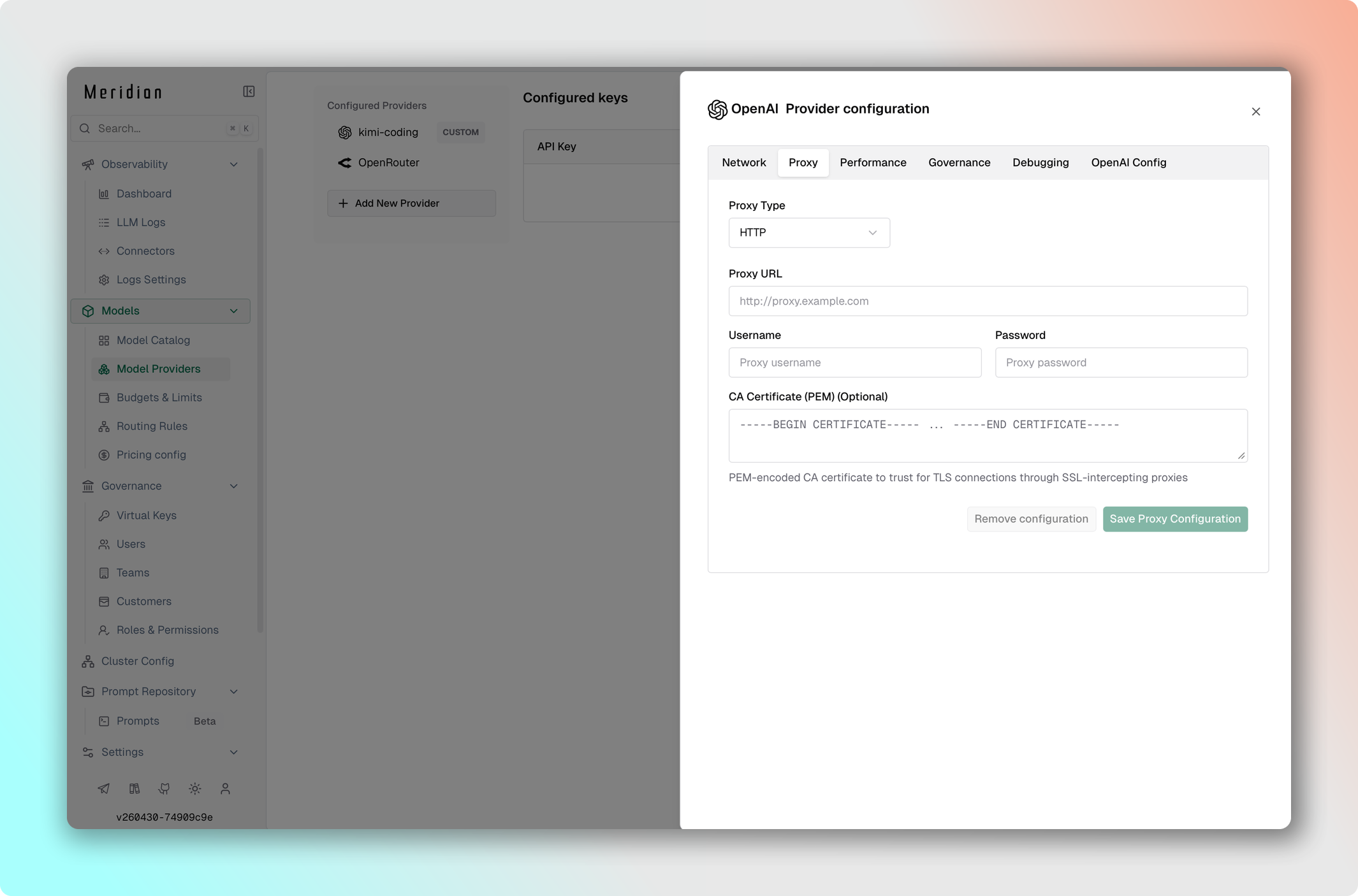
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Proxy config.
- Выберите Proxy Type: HTTP или SOCKS5.
- Установите Proxy URL:
http://localhost:8000. - При необходимости добавьте имя пользователя и пароль.
- Сохраните изменения.
# HTTP-прокси для OpenAI
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"proxy_config": {
"type": "http",
"url": "http://localhost:8000"
}
}'
# SOCKS5 с аутентификацией для Anthropic
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "anthropic",
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"proxy_config": {
"type": "socks5",
"url": "http://localhost:8000",
"username": "user",
"password": "password"
}
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"proxy_config": {
"type": "http",
"url": "http://localhost:8000"
}
},
"anthropic": {
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"proxy_config": {
"type": "socks5",
"url": "http://localhost:8000",
"username": "user",
"password": "password"
}
}
}
}Возврат сырого ответа
Возвращайте оригинальный ответ провайдера вместе со стандартизированным ответом Meridian. Пригодится для отладки и доступа к специфическим метаданным провайдера.
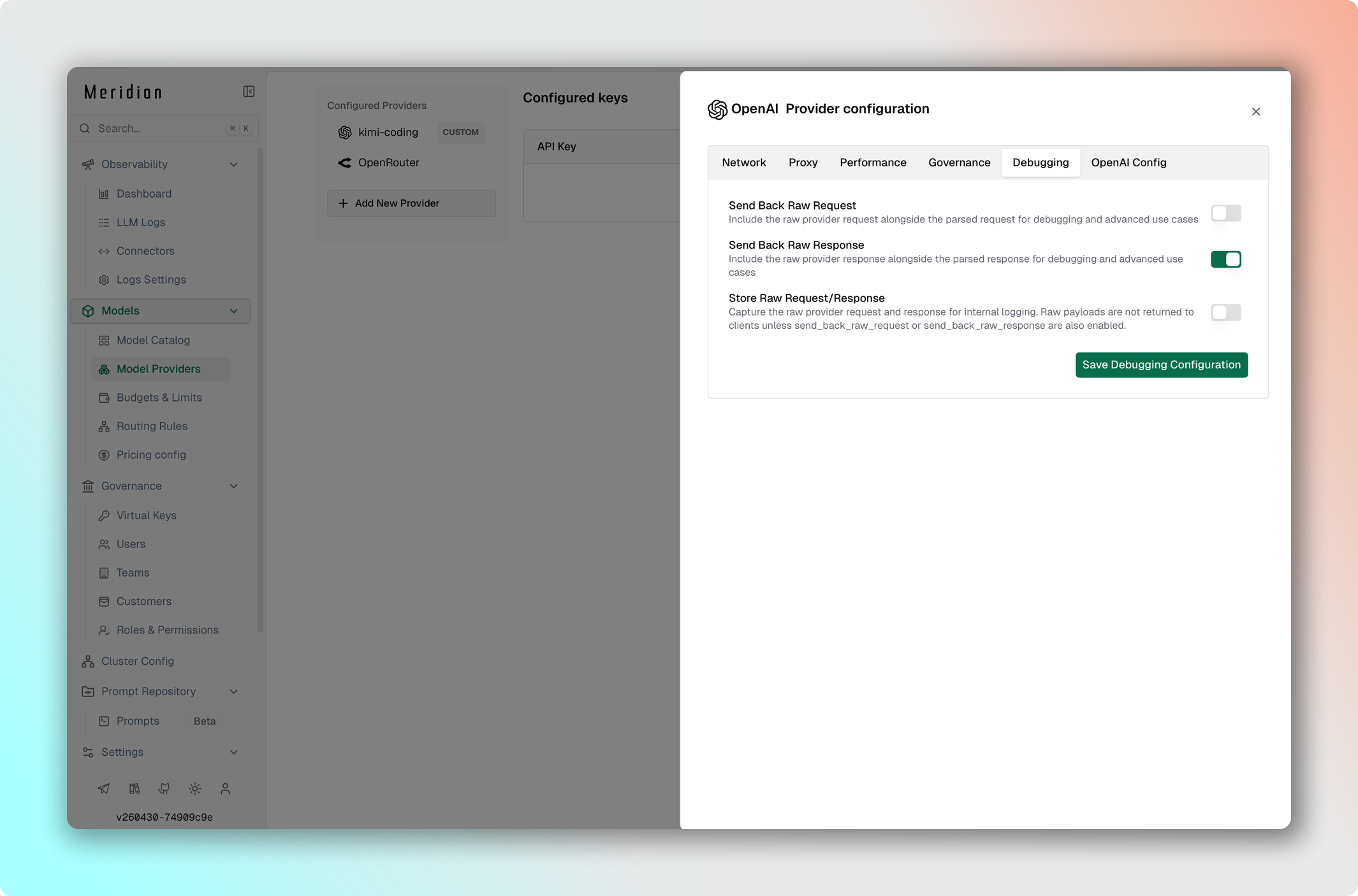
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Debugging.
- Включите тумблер Include Raw Response.
- Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"send_back_raw_response": true
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"send_back_raw_response": true
}
}
}При включении сырой ответ провайдера попадает в extra_fields.raw_response:
{
"choices": [...],
"usage": {...},
"extra_fields": {
"provider": "openai",
"raw_response": {
// Здесь оригинальный ответ OpenAI
}
}
}Возврат сырого запроса
Возвращайте оригинальный запрос, отправленный провайдеру, вместе с ответом Meridian. Полезно для отладки трансформаций запроса и проверки того, что именно ушло провайдеру.
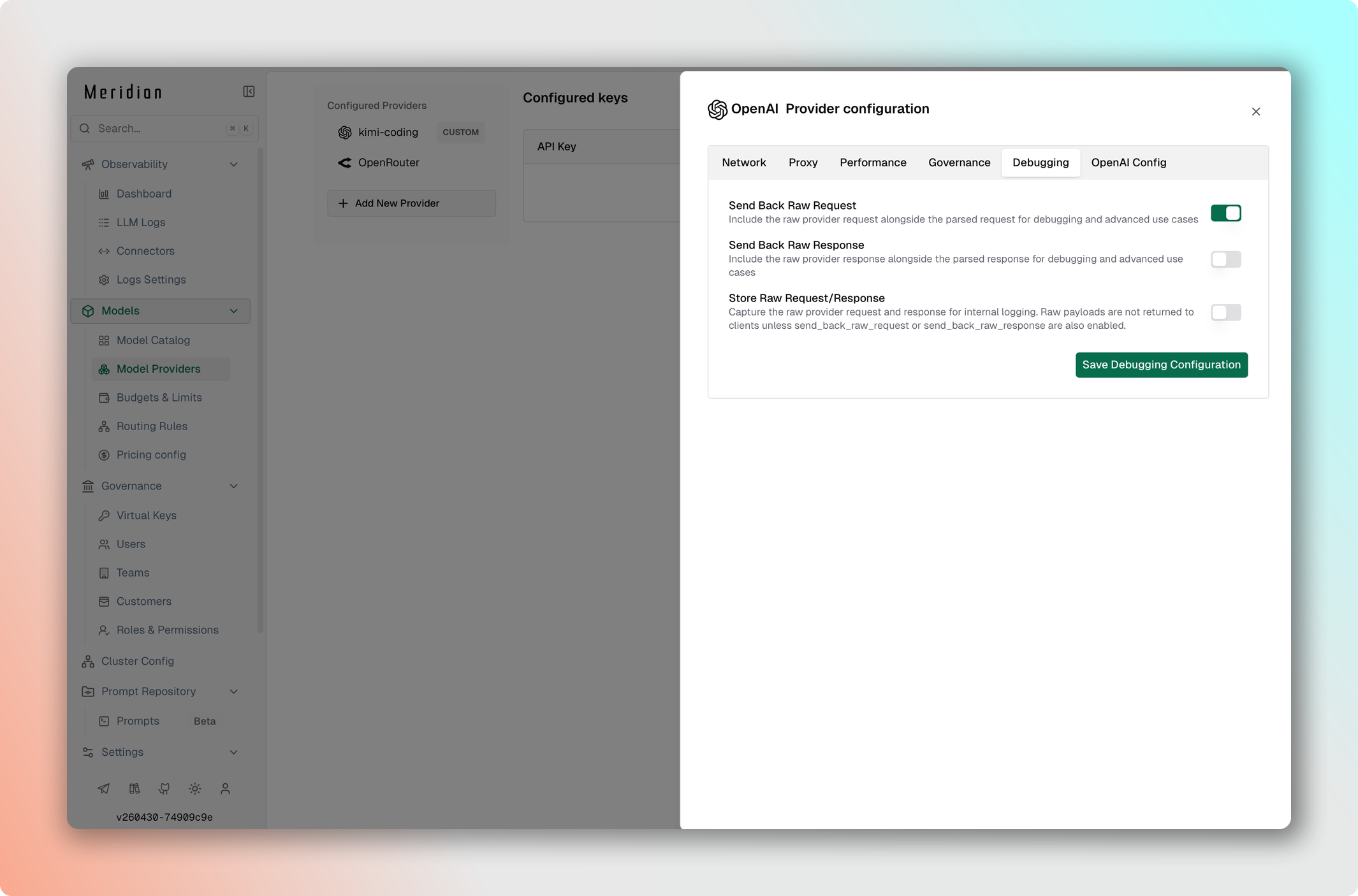
- Перейдите в Model Providers → Выберите провайдер → Edit Provider Config → Debugging.
- Включите тумблер Include Raw Request.
- Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"send_back_raw_request": true
}'{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"send_back_raw_request": true
}
}
}При включении сырой запрос к провайдеру попадает в extra_fields.raw_request:
{
"choices": [...],
"usage": {...},
"extra_fields": {
"provider": "openai",
"raw_request": {
// Здесь оригинальный запрос, ушедший в OpenAI
}
}
}send_back_raw_request и send_back_raw_response можно включить одновременно, чтобы видеть полный цикл запрос-ответ при отладке.
Passthrough дополнительных параметров
Включите passthrough-режим для дополнительных параметров. В этом режиме всё, что находится в поле extra_params (или в provider-specific полях для дополнительных параметров), мерджится напрямую в запрос к провайдеру в обход фильтрации Meridian.
curl --location 'http://localhost:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'x-bf-passthrough-extra-params: true' \
--data '{
"model": "openai/gpt-4o-mini",
"messages": [
{"role": "user", "content": "Hello!"}
],
"extra_params": {
"custom_param": "value",
"another_param": 123,
"nested_param": {
"nested_key": "nested_value"
}
}
}'Дополнительные параметры мерджатся в JSON-тело запроса к провайдеру. Это позволяет передавать provider-specific параметры, которые Meridian не поддерживает «нативно».
- Работает только для JSON-запросов; multipart/form-data не поддерживаются.
- Параметры, которые Meridian уже обрабатывает (например,
addWatermark,enhancePrompt), не дублируются — они уходят туда, где должны быть. - Вложенные параметры (например,
parameters.custom_field) мерджатся рекурсивно с существующей вложенной структурой.
Аутентификация для отдельных провайдеров
Корпоративные провайдеры требуют дополнительной настройки помимо API-ключа. Ниже — настройка Azure, AWS Bedrock и Google Vertex с platform-specific аутентификацией.
Azure
Azure поддерживает три способа аутентификации: Managed Identity (DefaultAzureCredential), Entra ID (Service Principal) и Direct (API-ключ).
Managed Identity / DefaultAzureCredential
Оставьте поле API-ключа и поля Entra ID пустыми. Meridian использует DefaultAzureCredential, которая автоматически распознаёт managed identity на Azure VM, App Service, AKS и аналогичных окружениях. Заполните только endpoint, deployments и при необходимости api_version.
Azure Entra ID (Service Principal)
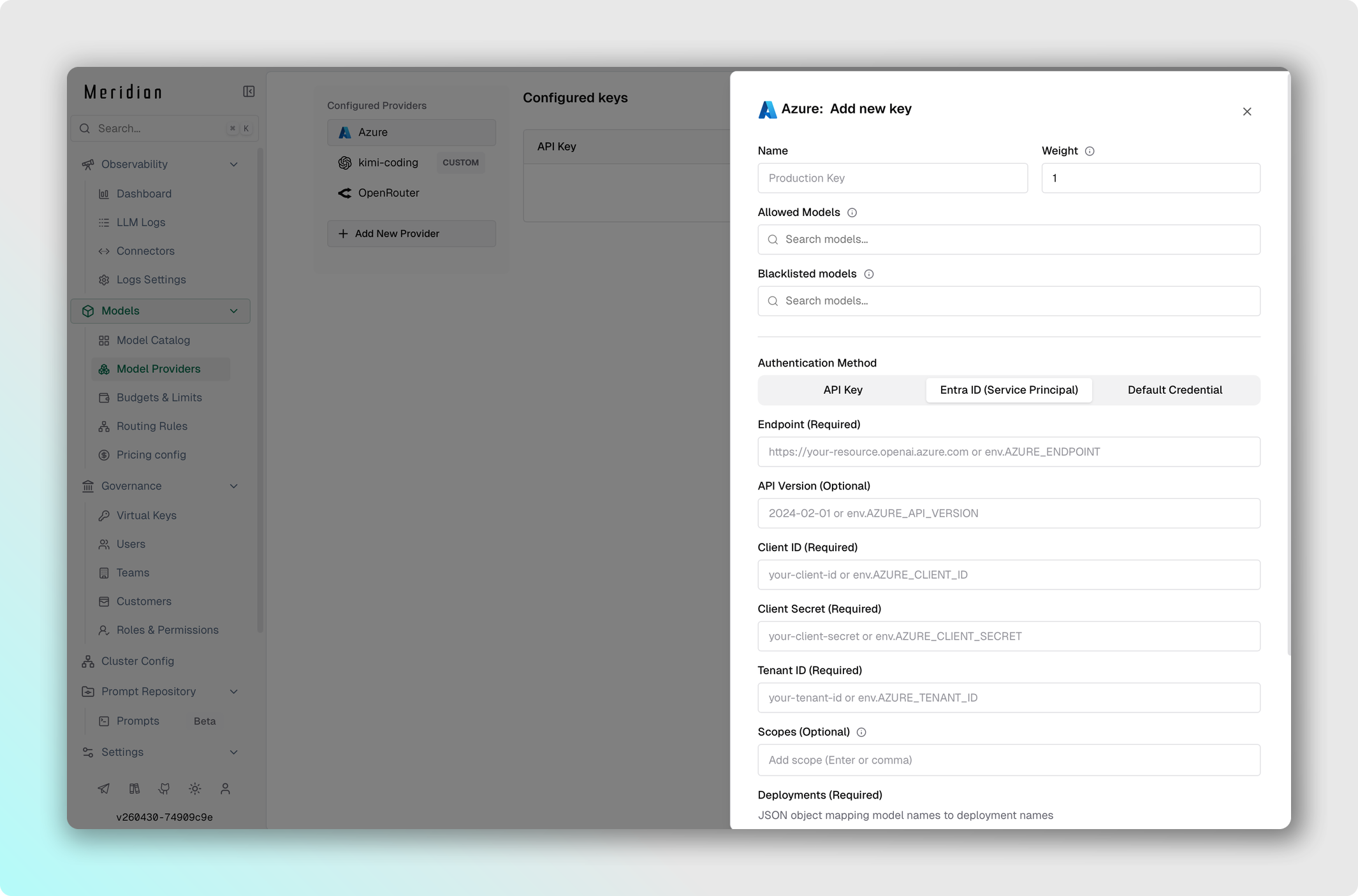
- Перейдите в Model Providers → Configurations → Azure.
- Оставьте API Key пустым для аутентификации через Service Principal.
- Установите Client ID — client ID из Azure Entra ID.
- Установите Client Secret — client secret из Azure Entra ID.
- Установите Tenant ID — tenant ID из Azure Entra ID.
- Установите Endpoint — URL вашего Azure-эндпоинта.
- Заполните Deployments — соответствие имён моделей и имён деплоймента.
- Установите API Version, например
2024-08-01-preview. - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "azure",
"keys": [
{
"name": "azure-key-1",
"value": "",
"models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0,
"azure_key_config": {
"endpoint": "env.AZURE_ENDPOINT",
"client_id": "env.AZURE_CLIENT_ID",
"client_secret": "env.AZURE_CLIENT_SECRET",
"tenant_id": "env.AZURE_TENANT_ID",
"scopes": ["https://cognitiveservices.azure.com/.default"],
"deployments": {
"gpt-4o": "gpt-4o-deployment",
"gpt-4o-mini": "gpt-4o-mini-deployment"
},
"api_version": "2024-08-01-preview"
}
}
]
}'{
"providers": {
"azure": {
"keys": [
{
"name": "azure-key-1",
"value": "",
"models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0,
"azure_key_config": {
"endpoint": "env.AZURE_ENDPOINT",
"client_id": "env.AZURE_CLIENT_ID",
"client_secret": "env.AZURE_CLIENT_SECRET",
"tenant_id": "env.AZURE_TENANT_ID",
"scopes": ["https://cognitiveservices.azure.com/.default"],
"deployments": {
"gpt-4o": "gpt-4o-deployment",
"gpt-4o-mini": "gpt-4o-mini-deployment"
},
"api_version": "2024-08-01-preview"
}
}
]
}
}
}Direct Authentication
Простейший вариант — задать ключ напрямую в поле value:
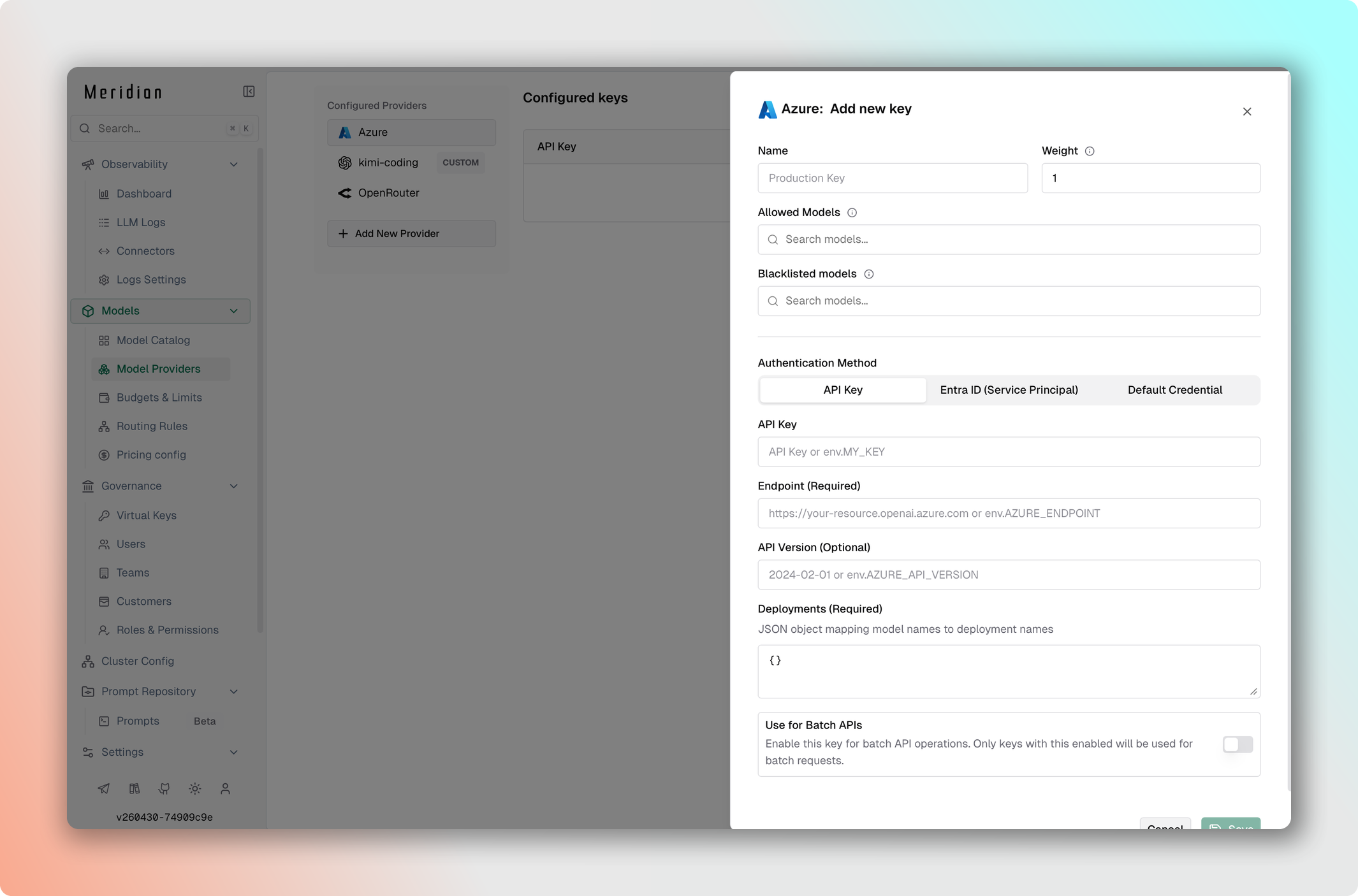
- Перейдите в Model Providers → Configurations → Azure.
- Установите API Key — ваш Azure API-ключ.
- Установите Endpoint — URL вашего Azure-эндпоинта.
- Заполните Deployments — соответствие имён моделей и имён деплоймента.
- Установите API Version, например
2024-08-01-preview. - Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "azure",
"keys": [
{
"name": "azure-key-1",
"value": "env.AZURE_API_KEY",
"models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0,
"azure_key_config": {
"endpoint": "env.AZURE_ENDPOINT",
"deployments": {
"gpt-4o": "gpt-4o-deployment",
"gpt-4o-mini": "gpt-4o-mini-deployment"
},
"api_version": "2024-08-01-preview"
}
}
]
}'{
"providers": {
"azure": {
"keys": [
{
"name": "azure-key-1",
"value": "env.AZURE_API_KEY",
"models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0,
"azure_key_config": {
"endpoint": "env.AZURE_ENDPOINT",
"deployments": {
"gpt-4o": "gpt-4o-deployment",
"gpt-4o-mini": "gpt-4o-mini-deployment"
},
"api_version": "2024-08-01-preview"
}
}
]
}
}
}Приоритет аутентификации Azure: (1) Entra ID — если заданы client_id, client_secret и tenant_id; (2) API-ключ — если задан value; (3) DefaultAzureCredential (managed identity) — если ни то, ни другое не задано.
AWS Bedrock
AWS Bedrock поддерживает явные креды и аутентификацию через IAM-роль:
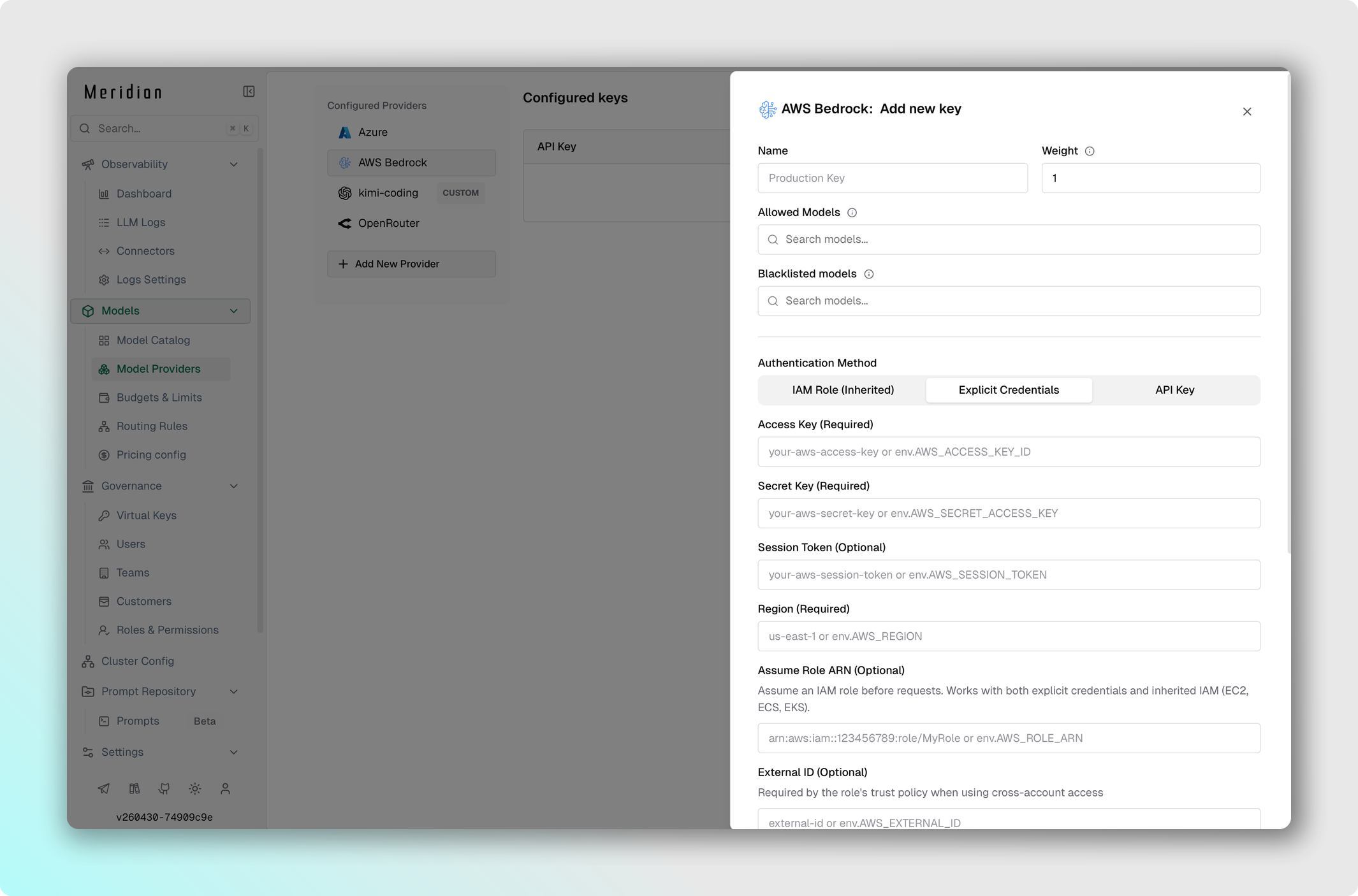
- Перейдите в Model Providers → Configurations → AWS Bedrock.
- Установите API Key — AWS API-ключ (или оставьте пустым при IAM-роли).
- Установите Access Key — AWS Access Key ID (или оставьте пустым, если используете IAM из окружения).
- Установите Secret Key — AWS Secret Access Key (или оставьте пустым, если используете IAM из окружения).
- Установите Region, например
us-east-1. - Заполните Deployments — соответствие имён моделей и inference-профилей.
- Установите ARN — обязателен при наличии deployments.
- Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "bedrock",
"keys": [
{
"name": "bedrock-key-1",
"models": ["anthropic.claude-3-sonnet-20240229-v1:0", "anthropic.claude-v2:1"],
"weight": 1.0,
"bedrock_key_config": {
"access_key": "env.AWS_ACCESS_KEY_ID",
"secret_key": "env.AWS_SECRET_ACCESS_KEY",
"session_token": "env.AWS_SESSION_TOKEN",
"region": "us-east-1",
"deployments": {
"claude-3-sonnet": "us.anthropic.claude-3-sonnet-20240229-v1:0"
},
"arn": "arn:aws:bedrock:us-east-1:123456789012:inference-profile"
}
}
]
}'{
"providers": {
"bedrock": {
"keys": [
{
"name": "bedrock-key-1",
"models": ["anthropic.claude-3-sonnet-20240229-v1:0", "anthropic.claude-v2:1"],
"weight": 1.0,
"bedrock_key_config": {
"access_key": "env.AWS_ACCESS_KEY_ID",
"secret_key": "env.AWS_SECRET_ACCESS_KEY",
"session_token": "env.AWS_SESSION_TOKEN",
"region": "us-east-1",
"deployments": {
"claude-3-sonnet": "us.anthropic.claude-3-sonnet-20240229-v1:0"
},
"arn": "arn:aws:bedrock:us-east-1:123456789012:inference-profile"
}
}
]
}
}
}Замечания:
- При API-Key аутентификации задайте
valueравным API-ключу; при IAM-роли оставьте пустым. - Если
access_keyиsecret_keyпусты, Meridian берёт IAM-роль из окружения. - Поле
arnобязательно для построения URL — без негоdeploymentsигнорируются. - При
arn+deploymentsMeridian использует model-профили; иначе путь формируется напрямую из имени модели в запросе. - В
arnкладите префикс ARN, вdeployments— только идентификатор inference-профиля или модели; полный ARN вdeploymentsпомещать не нужно.
Google Vertex
Google Vertex требует параметров проекта и аутентификационных данных:
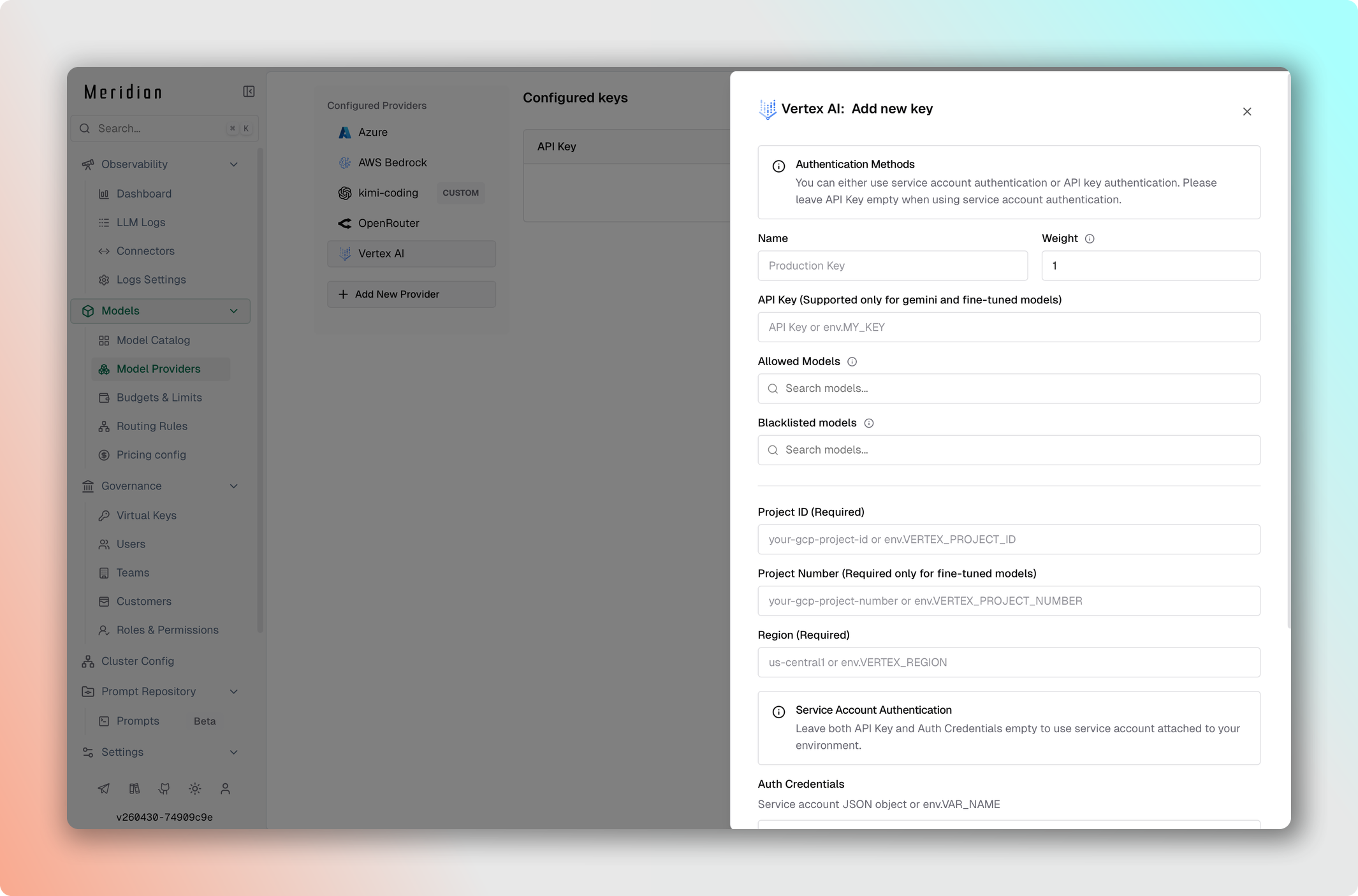
- Перейдите в Model Providers → Configurations → Google Vertex.
- Установите API Key — Vertex API-ключ.
- Установите Project ID — идентификатор проекта Google Cloud.
- Установите Region, например
us-central1. - Установите Auth Credentials — JSON service account credentials.
- Сохраните изменения.
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "vertex",
"keys": [
{
"name": "vertex-key-1",
"value": "env.VERTEX_API_KEY",
"models": ["gemini-pro", "gemini-pro-vision"],
"weight": 1.0,
"vertex_key_config": {
"project_id": "env.VERTEX_PROJECT_ID",
"region": "us-central1",
"auth_credentials": "env.VERTEX_CREDENTIALS",
"deployments": {
"fine-tuned-gemini-2.5-pro": "123456789"
}
}
}
]
}'{
"providers": {
"vertex": {
"keys": [
{
"name": "vertex-key-1",
"value": "env.VERTEX_API_KEY",
"models": ["gemini-pro", "gemini-pro-vision"],
"weight": 1.0,
"vertex_key_config": {
"project_id": "env.VERTEX_PROJECT_ID",
"region": "us-central1",
"auth_credentials": "env.VERTEX_CREDENTIALS",
"deployments": {
"fine-tuned-gemini-2.5-pro": "123456789"
}
}
}
]
}
}
}Замечания:
- Если оставить и API Key, и Auth Credentials пустыми, Meridian использует service account из окружения.
- Для fine-tuned моделей в Key config обязательно указывайте Project Number.
- Аутентификация по API-ключу поддерживается только для Gemini и fine-tuned моделей.
- Произвольные fine-tuned модели можно вызывать как
vertex/<your-fine-tuned-model-id>илиvertex/<model-deployment-alias>— если соответствие задано вdeployments.
Поддержка Vertex AI для fine-tuned моделей сейчас в beta. Запросы к не-Gemini fine-tuned моделям могут не работать; пожалуйста, тестируйте и сообщайте о проблемах.