Семантическое кеширование
Интеллектуальное кэширование ответов на основе семантической близости. Снижает стоимость и задержку за счёт выдачи закэшированных ответов на семантически близкие запросы.
Обзор
Semantic caching использует поиск по векторной близости, чтобы интеллектуально кэшировать ответы AI и отдавать закэшированные результаты для семантически похожих запросов даже при иной формулировке. Это значительно снижает расходы на API и задержки для повторяющихся или похожих запросов.
Ключевые преимущества:
- Снижение стоимости — отказ от дорогостоящих вызовов LLM API для похожих запросов.
- Рост производительности — субмиллисекундное чтение из кэша вместо многосекундных вызовов API.
- Интеллектуальный матчинг — семантическая близость, а не только текстовое совпадение.
- Поддержка streaming — кэширование стриминговых ответов с корректным порядком чанков.
Основные возможности
- Двухслойное кэширование — точное совпадение по хэшу + поиск по семантической близости (порог настраивается).
- Векторный матчинг — embedding-ы используются для поиска семантически близких запросов.
- Динамическая конфигурация — TTL и порог переопределяются на уровне запроса через заголовки.
- Изоляция по модели/провайдеру — отдельный кэш на комбинацию модели и провайдера.
Подготовка vector store
Semantic caching требует настроенного vector store. Meridian поддерживает следующие векторные базы:
- Weaviate — production-ready векторная БД с gRPC.
- Redis / Valkey — высокопроизводительный in-memory vector store на API, совместимых с RediSearch.
- Qdrant — поисковый движок на Rust с продвинутой фильтрацией.
- Pinecone — managed-сервис векторной БД с serverless-опциями.
Быстрый пример (Weaviate):
{
"vector_store": {
"enabled": true,
"type": "weaviate",
"config": {
"host": "localhost:8080",
"scheme": "http"
}
}
}Конфигурация semantic cache
Текущий веб-интерфейс настраивает provider-backed semantic caching. Если нужен direct-only режим (dimension: 1 без provider), настраивайте через config.json.
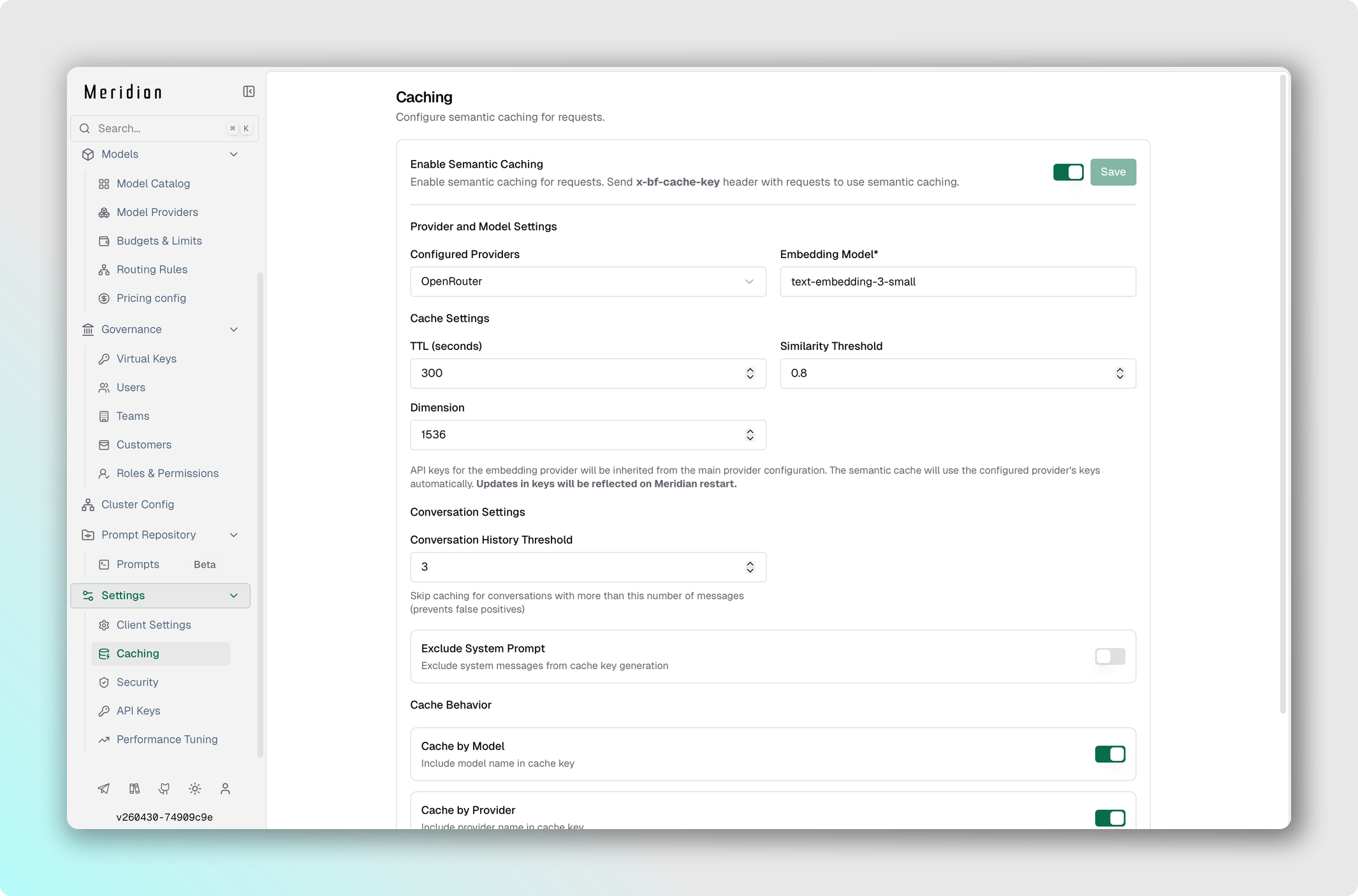
Перед настройкой плагина semantic cache убедитесь, что у вас уже сконфигурирован vector store (через config.json).
-
Перейдите в настройки
- Откройте Meridian UI на
http://localhost:8080. - Перейдите в Settings.
- Откройте Meridian UI на
-
Настройте плагин semantic cache
- Включите тумблер плагина и заполните обязательные поля.
Обязательные поля:
- Provider — провайдер для embedding-ов кэша.
- Embedding Model — embedding-модель.
- Dimension — размерность embedding-ов выбранной модели.
Изменения требуют перезапуска сервера Meridian, так как плагин загружается только на старте.
{
"plugins": [
{
"enabled": true,
"name": "semantic_cache",
"config": {
"provider": "openai",
"embedding_model": "text-embedding-3-small",
"dimension": 1536,
"cleanup_on_shutdown": true,
"ttl": "5m",
"threshold": 0.8,
"conversation_history_threshold": 3,
"exclude_system_prompt": false,
"cache_by_model": true,
"cache_by_provider": true
}
}
]
}В сценариях с config.json ключи провайдера берутся из его конфигурации при инициализации, поэтому дублировать keys внутри плагина не нужно. Любые изменения ключей провайдера применяются только после перезапуска.
Форматы TTL:
- Строки длительности:
"30s","5m","1h","24h". - Числовые секунды:
300(5 минут),3600(1 час).
Direct hash mode (без embedding-ов)
Direct hash mode обеспечивает точное кэширование без обращения к embedding-провайдеру. Каждый запрос детерминированно хэшируется на основе нормализованного входа, параметров и флага streaming. Идентичные запросы попадают в кэш; иная формулировка — это cache miss.
Точные direct-записи сохраняются и читаются по детерминированному cache ID. Это обеспечивает быстрый и стабильный поиск при retry, streaming и перезапусках.
Когда использовать direct hash mode:
- Нужна только точная дедупликация (без fuzzy/семантического матчинга).
- Невозможно или нежелательно вызывать внешний embedding API.
- Нужна минимальная задержка без накладных расходов на embedding.
- Cost-sensitive окружения, где вызовы embedding API накапливают стоимость.
Настройка
Чтобы включить direct-only режим глобально, выставьте dimension: 1 и не указывайте поля provider и keys в конфиге плагина. Плагин автоматически переключится только на direct-поиск.
Если задать dimension: 1 и при этом указать provider, Meridian будет считать конфигурацию provider-backed semantic mode, а не direct-only. Чтобы использовать direct-only, поле provider должно отсутствовать полностью.
Vector store по-прежнему обязателен как backend хранения, даже в direct hash mode. См. раздел Рекомендуемый vector store ниже.
{
"plugins": [
{
"enabled": true,
"name": "semantic_cache",
"config": {
"dimension": 1,
"ttl": "5m",
"cleanup_on_shutdown": true,
"cache_by_model": true,
"cache_by_provider": true
}
}
]
}При такой инициализации все запросы автоматически используют direct hash matching независимо от заголовка x-bf-cache-type. Embedding-ы не вычисляются, и креды embedding-провайдера не нужны.
Рекомендуемый vector store
Для direct hash mode рекомендованы Redis/Valkey-совместимые хранилища. Им не требуются векторы для metadata-only записей, а все поля кэша индексируются как TAG-поля для быстрого точного поиска.
Qdrant и Pinecone несовместимы с direct hash mode без настроенного embedding-провайдера. Эти стораджи требуют вектор для каждой записи; кодовый путь zero-vector в плагине требует инициализированного embedding-клиента, поэтому запись не выполнится без провайдера. Weaviate тоже требует вектор на запись и не рекомендован для direct-only режима.
{
"vector_store": {
"enabled": true,
"type": "redis",
"config": {
"addr": "localhost:6379"
}
}
}Для развёртываний на Valkey оставьте vector_store.type равным "redis" и направьте config.addr на ваш Valkey-эндпоинт.
Переопределение типа кэша на уровне запроса
Если плагин инициализирован без embedding-провайдера (direct-only режим), все запросы автоматически используют direct hash matching. Заголовок x-bf-cache-type в этом случае не влияет.
Если плагин инициализирован с embedding-провайдером (двухслойный режим), вы можете принудительно использовать direct-only матчинг для конкретных запросов через заголовок x-bf-cache-type: direct. Подробнее — в разделе Управление типом кэша.
Активация кэша
Cache key обязателен: semantic caching активируется только при наличии cache key. Без него запросы полностью обходят кэш.
Cache key задаётся в HTTP-заголовке x-bf-cache-key:
# Этот запрос БУДЕТ кэширован
curl -H "x-bf-cache-key: session-123" ...
# Этот запрос НЕ будет кэширован (нет заголовка)
curl ...Переопределения на уровне запроса
Дефолтные TTL и порог сходства можно переопределить для конкретного запроса заголовками x-bf-cache-ttl и x-bf-cache-threshold:
# Кастомные TTL и threshold
curl -H "x-bf-cache-key: session-123" \
-H "x-bf-cache-ttl: 30s" \
-H "x-bf-cache-threshold: 0.9" ...Расширенное управление кэшем
Управление типом кэша
Управляйте механизмом кэширования на уровне запроса:
# Только direct hash matching
curl -H "x-bf-cache-key: session-123" \
-H "x-bf-cache-type: direct" ...
# Только семантический поиск
curl -H "x-bf-cache-key: session-123" \
-H "x-bf-cache-type: semantic" ...
# По умолчанию: direct + semantic fallback (если заголовок не задан)
curl -H "x-bf-cache-key: session-123" ...No-store
Чтобы читать из кэша, но не сохранять ответ, используйте заголовок x-bf-cache-no-store: true:
curl -H "x-bf-cache-key: session-123" \
-H "x-bf-cache-no-store: true" ...Параметры разговора
Логика порога истории
Параметр conversation_history_threshold пропускает кэширование для разговоров с большим числом сообщений, чтобы предотвратить ложные срабатывания.
Почему это важно:
- Семантические false positives — длинная история разговора с высокой вероятностью даёт семантические совпадения с несвязанными разговорами из-за пересечения тем.
- Неэффективность direct cache — у длинных разговоров редко совпадают точные хэши, что снижает эффективность direct-кэширования.
- Производительность — снижается нагрузка на vector store за счёт отсечения малоценных сценариев кэширования.
{
"conversation_history_threshold": 3
}Рекомендуемые значения:
- 1–2 — крайне консервативно (можно упустить полезные кэш-попадания).
- 3–5 — сбалансированный подход (по умолчанию: 3).
- 10+ — кэширование длинных разговоров (выше риск false positive).
Обработка системного промпта
Управляет включением system-сообщений в ключ кэша:
{
"exclude_system_prompt": false
}Когда исключать (true):
- System-промпты часто меняются, но содержание похоже.
- Несколько вариаций system-промпта для одного и того же сценария.
- Кэширование сосредоточено на схожести пользовательского контента.
Когда включать (false):
- System-промпт значительно меняет поведение модели.
- Каждый system-промпт требует отдельных кэшированных ответов.
- Жёсткие требования к консистентности ответов.
Управление кэшем
Метаданные кэша в ответе
Когда ответ выдаётся из semantic cache, в ответ добавляются ключевые поля.
Расположение: response.ExtraFields.CacheDebug (как JSON-объект).
Поля:
CacheHit(boolean) —true, если ответ из кэша;falseпри промахе.HitType(string) —"semantic"для совпадения по близости,"direct"для совпадения по хэшу.CacheID(string) — уникальный ID записи кэша для операций управления (только при попадании).
Только для semantic cache:
ProviderUsed(string) — провайдер, использованный для embedding-а семантического матчинга (для попадания и промаха).ModelUsed(string) — embedding-модель (для попадания и промаха).InputTokens(number) — число токенов, извлечённых из запроса для расчёта embedding-а (для попадания и промаха).Threshold(number) — порог сходства, использованный при матчинге (только при попадании).Similarity(number) — оценка сходства (только при попадании).
Пример HTTP-ответа:
{
"extra_fields": {
"cache_debug": {
"cache_hit": true,
"hit_type": "direct",
"cache_id": "550e8500-e29b-41d4-a725-446655440001"
}
}
}{
"extra_fields": {
"cache_debug": {
"cache_hit": true,
"hit_type": "semantic",
"cache_id": "550e8500-e29b-41d4-a725-446655440001",
"threshold": 0.8,
"similarity": 0.95,
"provider_used": "openai",
"model_used": "gpt-4o-mini",
"input_tokens": 100
}
}
}{
"extra_fields": {
"cache_debug": {
"cache_hit": false,
"provider_used": "openai",
"model_used": "gpt-4o-mini",
"input_tokens": 20
}
}
}Эти поля позволяют детектировать кэшированные ответы и получать ID записи для адресной очистки.
Удаление конкретной записи
Используйте request ID из ответа для удаления конкретной записи:
# Удалить запись кэша по request ID
curl -X DELETE http://localhost:8080/api/cache/clear/550e8400-e29b-41d4-a716-446655440000
# Удалить все записи по cache key
curl -X DELETE http://localhost:8080/api/cache/clear-by-key/support-session-456Жизненный цикл и очистка
Semantic cache автоматически выполняет очистку, чтобы избежать разрастания хранилища.
Автоматическая очистка:
- Истечение TTL — записи удаляются по истечении TTL.
- Очистка при остановке — все записи и сам namespace очищаются в vector store при остановке клиента Meridian.
- Изоляция namespace — каждый инстанс Meridian использует свой namespace в vector store во избежание конфликтов.
Ручная очистка:
- Удаление конкретных записей по request ID (см. пример выше).
- Удаление всех записей по cache key.
- Перезапуск Meridian для очистки всего кэша.
Namespace semantic cache и все его записи удаляются при остановке клиента Meridian только если cleanup_on_shutdown равно true. По умолчанию (cleanup_on_shutdown: false) данные кэша сохраняются между перезапусками. НЕ используйте namespace плагина для внешних целей.
Изменение размерности: при обновлении поля dimension существующий namespace будет содержать данные с разной размерностью, что приведёт к проблемам поиска. Чтобы избежать этого, используйте либо другой vector_store_namespace, либо выставьте cleanup_on_shutdown: true перед перезапуском.
Требование к vector store: semantic caching требует настроенного vector store. Meridian поддерживает Weaviate, эндпоинты, совместимые с Redis/Valkey, Qdrant и Pinecone.
Управление ролями (RBAC)
Контроль доступа к ресурсам Meridian через роли. Три встроенные роли с фиксированной матрицей разрешений, защита от self-lockout и инвалидация сессий при смене роли.
Кластеризация
Высокодоступное развёртывание Meridian на нескольких нодах с peer-to-peer-архитектурой, gossip-протоколом и Raft-координацией бюджетов.