Маршрутизация запросов к провайдерам
Как Meridian маршрутизирует запросы между LLM-провайдерами через governance-правила и адаптивную балансировку.
Обзор
Meridian предлагает два мощных механизма распределения запросов между провайдерами, каждый под свои сценарии:
- Governance-routing — явные пользовательские правила маршрутизации, заданные через виртуальные ключи.
- Адаптивная балансировка — автоматическая маршрутизация по производительности, основанная на метриках в реальном времени (Enterprise).
Когда оба механизма доступны, приоритет у governance — пользователь явно задал свои предпочтения через provider configurations виртуальных ключей.
Что и когда выбирать:
- Governance — нужен явный контроль, требования compliance или конкретная стратегия оптимизации стоимости.
- Adaptive Load Balancing — автоматическая оптимизация производительности с минимальной настройкой.
Каталог моделей (Model Catalog)
Каталог моделей — это центральный реестр Meridian, отслеживающий, какие модели доступны у каких провайдеров. Он питает и governance-routing, и адаптивную балансировку, поддерживая в актуальном состоянии маппинг «модель → провайдер».
Источники данных
Каталог объединяет два источника:
-
Pricing-данные (основной источник).
- Скачиваются с удалённого URL (настраиваемый, по умолчанию
https://meridian.neria.cloud/datasheet). - Содержат имена моделей, тарифы и сопоставление с провайдерами.
- Синхронизируются в БД при старте и периодически обновляются (по умолчанию раз в 24 часа).
- Используются для расчёта стоимости и первичного маппинга.
- Хранение: in-memory map
pricingData[model|provider|mode]с O(1)-доступом.
- Скачиваются с удалённого URL (настраиваемый, по умолчанию
-
List Models API провайдеров (вторичный источник).
- Запрос к эндпоинту
/v1/modelsкаждого провайдера при старте. - Обогащает каталог provider-specific моделями и алиасами.
- Перезапрашивается при добавлении/обновлении провайдера через API или панель управления.
- Добавляет модели, которых ещё нет в pricing-данных (например, только что выпущенные).
- Хранение: in-memory map
modelPool[provider][]models.
- Запрос к эндпоинту
Зачем два источника? Pricing-данные дают полное покрытие моделей с информацией о стоимости, а List Models API позволяет использовать новые модели, не дожидаясь обновления pricing-данных.
Как определяется доступность модели
Поведение синхронизации
Поведение allowed_models с примерами
Поле allowed_models в provider-конфигах определяет, какие модели можно использовать с данным провайдером. Понимание его поведения критично для governance-routing.
Конфигурация:
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["*"],
"weight": 1.0
}
]
}Поведение:
- Meridian вызывает
GetModelsForProvider("openai"). - Возвращает все модели из
modelPool["openai"]. - Запрос валидируется по каталогу.
Примеры:
# ✅ Разрешено (есть в каталоге)
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-4o"}'
# ✅ Разрешено
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-3.5-turbo"}'
# ❌ Отклонено (нет в каталоге OpenAI)
curl -H "x-bf-vk: vk-123" -d '{"model": "claude-3-5-sonnet"}'Сценарии:
- значение по умолчанию для большинства развёртываний;
- автоматически синхронизируется с пулом моделей провайдера;
- не требует ручного ведения списков.
"allowed_models": [] (пустой массив) означает deny all — ни один запрос не пройдёт. Используйте ["*"], чтобы разрешить все модели через каталог.
Конфигурация:
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o", "gpt-4o-mini"],
"weight": 1.0
},
{
"provider": "anthropic",
"allowed_models": ["claude-3-5-sonnet-20241022"],
"weight": 1.0
}
]
}Поведение:
- Meridian валидирует модель по явному списку;
- каталог в этом случае игнорируется;
- поддерживаются прямые совпадения и записи с префиксом провайдера;
- сравнение чувствительно к регистру.
Примеры:
# ✅ Разрешено
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-4o"}'
# ❌ Отклонено (нет в списке)
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-4-turbo"}'
# даже если gpt-4-turbo есть в каталоге OpenAI
# ✅ Разрешено
curl -H "x-bf-vk: vk-123" -d '{"model": "claude-3-5-sonnet-20241022"}'
# ❌ Отклонено (несовпадение версии)
curl -H "x-bf-vk: vk-123" -d '{"model": "claude-3-5-sonnet-20240620"}'Записи с префиксом провайдера. Можно использовать имена моделей с префиксом — Meridian снимет префикс и сравнит с запрошенной моделью:
{
"provider_configs": [
{
"provider": "openrouter",
"allowed_models": ["openai/gpt-4o", "anthropic/claude-3-5-sonnet"],
"weight": 1.0
}
]
}Как это работает:
# Запрос без префикса
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-4o"}'
# 1. Проверяется: "openai/gpt-4o" в allowed_models
# 2. Префикс снимается: "openai/gpt-4o" → "gpt-4o"
# 3. Сравнение: "gpt-4o" == "gpt-4o" ✅
# 4. Результат: разрешено и маршрутизируется в OpenRouterОсобенно полезно для proxy-провайдеров (OpenRouter, Vertex), где нужно явно ограничить, какие upstream-модели доступны.
Сценарии:
- compliance (только утверждённые модели);
- контроль расходов (только дешёвые модели);
- pin версии (защита от автообновления);
- тестирование конкретных версий;
- явный cross-provider routing (например, разрешить только OpenAI-модели через OpenRouter).
Ключевое: deployments — это key-specific маппинги, позволяющие подменять провайдеро-специфические идентификаторы deployment'ов на удобные имена моделей.
Как работает:
- задаётся на уровне ключа, не виртуального ключа;
- структура:
deployments: {"alias": "deployment-id"}; - alias (слева) — имя модели в запросе пользователя;
- deployment ID (справа) — провайдеро-специфический идентификатор, уходящий в API.
Azure OpenAI:
{
"providers": {
"azure": {
"keys": [
{
"name": "azure-prod-key",
"value": "your-api-key",
"models": [],
"azure_key_config": {
"endpoint": "https://your-resource.openai.azure.com",
"deployments": {
"gpt-4o": "my-prod-gpt4o-deployment",
"gpt-4o-mini": "my-mini-deployment"
}
}
}
]
}
}
}Что происходит:
- Allowed models выводится из алиасов:
["gpt-4o", "gpt-4o-mini"]. - Запрос с алиасом:
{"model": "gpt-4o"}. - Валидация:
gpt-4oесть в выведенных allowed models ✅. - Маппинг:
gpt-4o→my-prod-gpt4o-deployment. - В Azure: используется
my-prod-gpt4o-deployment. - Pricing: если для deployment'а pricing нет, fallback на алиас
gpt-4o.
Bedrock с inference-профилями:
{
"providers": {
"bedrock": {
"keys": [
{
"name": "bedrock-key",
"models": [],
"bedrock_key_config": {
"access_key": "your-access-key",
"secret_key": "your-secret-key",
"region": "us-east-1",
"deployments": {
"claude-sonnet": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"claude-opus": "us.anthropic.claude-3-opus-20240229-v1:0"
}
}
}
]
}
}
}Приоритет ограничений модели. При вычислении allowed models для ключа:
1. Если key.models НЕ пуст → используется key.models
2. Иначе если есть deployments → используются алиасы deployments
3. Иначе → разрешены все модели (через Model Catalog)Пример с обоими:
{
"keys": [
{
"models": ["gpt-4o", "gpt-3.5-turbo"],
"azure_key_config": {
"deployments": {
"gpt-4o": "my-deployment",
"gpt-4-turbo": "another-deployment"
}
}
}
]
}Результат: разрешены только ["gpt-4o", "gpt-3.5-turbo"] — models имеет приоритет.
Vertex (тот же паттерн):
{
"keys": [
{
"vertex_key_config": {
"project_id": "my-project",
"region": "us-central1",
"deployments": {
"claude-3-5-sonnet": "anthropic/claude-3-5-sonnet@20241022",
"gemini-pro": "google/gemini-1.5-pro"
}
}
}
]
}Сценарии:
- Azure — маппинг общих имён моделей на конкретные имена deployment'ов в Azure-ресурсе;
- Bedrock — короткие алиасы для длинных ARN inference-профилей;
- Vertex — конкретные версии моделей или региональные эндпоинты;
- Окружения — разные deployment'ы в разных ключах (dev/staging/prod).
Ключевая идея:
Запрос: {"model": "gpt-4o"}
↓
Валидация: "gpt-4o" в allowed models (выведенных из deployments)
↓
Маппинг: deployments["gpt-4o"] → "my-prod-gpt4o-deployment"
↓
API-вызов: используется "my-prod-gpt4o-deployment"
↓
Pricing: fallback на "gpt-4o", если deployment'а нет в pricing-данныхКонфигурация:
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o"],
"weight": 0.5
},
{
"provider": "azure",
"allowed_models": ["gpt-4o"],
"weight": 0.5
}
]
}Запрос:
curl -H "x-bf-vk: vk-123" \
-d '{"model": "gpt-4o"}'Поведение:
- Валидация: оба провайдера содержат
gpt-4oвallowed_models✅. - Взвешенный выбор: 50/50.
- Выбран провайдер: допустим, Azure.
- Преобразование модели:
gpt-4o→azure/gpt-4o. - Fallbacks:
["openai/gpt-4o"](оставшиеся провайдеры).
Cross-provider сценарии:
OpenRouter как универсальный proxy.
{
"provider_configs": [
{
"provider": "openrouter",
"allowed_models": ["*"]
}
]
}Запрос claude-3-5-sonnet:
- Meridian проверяет
GetModelsForProvider("openrouter"). - Находит
anthropic/claude-3-5-sonnetв каталоге OpenRouter. - ✅ Разрешено, маршрутизируется в OpenRouter.
Взвешенный routing через proxy-провайдера. Сценарий: 99 % OpenAI-трафика отправлять через OpenRouter ради экономии, 1 % напрямую — для подстраховки.
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o"],
"weight": 0.01
},
{
"provider": "openrouter",
"allowed_models": ["openai/gpt-4o"],
"weight": 0.99
}
]
}Запрос gpt-4o:
- OpenAI:
"gpt-4o"в["gpt-4o"]→ ✅. - OpenRouter: снимает префикс с
"openai/gpt-4o"→ совпадает с"gpt-4o"→ ✅. - Взвешенный выбор: 99 % → OpenRouter.
- Финальная модель:
openrouter/gpt-4o. - Fallbacks:
["openai/gpt-4o"].
Vertex как мульти-провайдерный шлюз.
{
"provider_configs": [
{
"provider": "vertex",
"allowed_models": ["claude-3-5-sonnet", "gemini-1.5-pro"]
}
]
}Запрос claude-3-5-sonnet:
GetProvidersForModel("claude-3-5-sonnet")находит["anthropic", "vertex", "bedrock"].- Валидация по
allowed_models✅. - В Vertex уходит как
anthropic/claude-3-5-sonnet.
Совместимость Groq с OpenAI.
{
"provider_configs": [
{
"provider": "groq",
"allowed_models": ["gpt-3.5-turbo"]
}
]
}Запрос gpt-3.5-turbo:
- Специальная обработка: проверка каталога Groq на
openai/gpt-3.5-turbo. - ✅ Найдено, валидация прошла.
- В Groq уходит как
openai/gpt-3.5-turbo.
Как каталог используется в маршрутизации
Когда у виртуального ключа есть provider_configs, governance использует каталог для валидации.
Wildcard allowed_models:
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["*"],
"weight": 0.5
}
]
}Поток:
curl -H "x-bf-vk: vk-123" -d '{"model": "gpt-4o"}'
# 1. Governance: есть ли "gpt-4o" в GetModelsForProvider("openai")?
# 2. Каталог: modelPool["openai"] содержит "gpt-4o" ✅
# 3. Валидация прошла, провайдер выбран
# 4. Модель становится: "openai/gpt-4o"Отказ:
curl -H "x-bf-vk: vk-123" -d '{"model": "claude-3-5-sonnet"}'
# 1. Governance: есть ли "claude-3-5-sonnet" в GetModelsForProvider("openai")?
# 2. Каталог: modelPool["openai"] НЕ содержит "claude-3-5-sonnet" ❌
# 3. Валидация не прошла, запрос отклонён
# 4. Ошибка: "model not allowed for any configured provider"Балансировщик опрашивает каталог для поиска кандидатов.
Поток:
curl -X POST http://localhost:8080/v1/chat/completions \
-d '{"model": "gpt-4o", "messages": [...]}'
# 1. LB: GetProvidersForModel("gpt-4o")
# 2. Каталог: ["openai", "azure", "groq"]
# 3. Фильтр по настроенным провайдерам: ["openai", "azure"] (groq не настроен)
# 4. Скоринг: openai=0.95, azure=0.87
# 5. Выбран: openai
# 6. Модель: "openai/gpt-4o"
# 7. Fallbacks: ["azure/gpt-4o"]Cross-provider обнаружение:
curl -d '{"model": "claude-3-5-sonnet"}'
# 1. LB: GetProvidersForModel("claude-3-5-sonnet")
# 2. Проверки каталога:
# - Прямой: ["anthropic"] ✅
# - OpenRouter: содержит "anthropic/claude-3-5-sonnet" ✅
# - Vertex: содержит "anthropic/claude-3-5-sonnet" ✅
# - Bedrock: содержит "anthropic.claude-3-5-sonnet-..." ✅
# 3. Каталог: ["anthropic", "openrouter", "vertex", "bedrock"]
# 4. Скоринг по всем четырём
# 5. Выбран лучший по производительностиТак Meridian реализует умный cross-provider routing без ручной настройки.
Каталог моделей критичен для cross-provider routing. Без него Meridian не знал бы, что gpt-4o доступен у OpenAI, Azure и Groq, и что claude-3-5-sonnet маршрутизируется через Anthropic, Vertex, Bedrock и OpenRouter. Эти знания питают и governance-валидацию, и обнаружение провайдеров балансировщиком.
Governance-routing
Governance-routing позволяет явно задать провайдеров и модели, обслуживающих запросы для конкретного виртуального ключа. Этот метод даёт точный контроль над решениями маршрутизации.
Как это работает
Когда у виртуального ключа определены provider_configs:
- Запрос приходит с виртуальным ключом (например,
x-bf-vk: vk-prod-main). - Валидация модели: Meridian проверяет, разрешена ли модель хотя бы у одного настроенного провайдера.
- Фильтрация провайдеров по:
- наличию модели в
allowed_models; - бюджетам (текущее использование vs максимум);
- rate limit'ам (токены/запросы за окно).
- наличию модели в
- Взвешенный выбор: провайдер выбирается weighted random.
- Префикс провайдера: строка модели становится
provider/model(например,openai/gpt-4o). - Fallbacks: оставшиеся провайдеры сортируются по убыванию веса и добавляются как fallbacks.
Пример конфигурации
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o", "gpt-4o-mini"],
"weight": 0.3,
"budget": {
"max_limit": 100.0,
"current_usage": 45.0
}
},
{
"provider": "azure",
"allowed_models": ["gpt-4o"],
"weight": 0.7,
"rate_limit": {
"token_max_limit": 100000,
"token_reset_duration": "1m"
}
}
]
}Поток запроса
Запрос с виртуальным ключом:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [...]}'Оценка governance:
- OpenAI: ✅
gpt-4oвallowed_models, бюджет в порядке, вес 0.3. - Azure: ✅
gpt-4oвallowed_models, rate limit в порядке, вес 0.7.
Взвешенный выбор:
- 70 % → Azure;
- 30 % → OpenAI.
Преобразование запроса:
{
"model": "azure/gpt-4o",
"messages": [...],
"fallbacks": ["openai/gpt-4o"]
}Возможности
| Возможность | Описание |
|---|---|
| Явный контроль | Точный список провайдеров и моделей |
| Бюджет | Автоматическое исключение провайдеров с превышением бюджета |
| Rate limit | Пропуск провайдеров, упирающихся в лимиты |
| Веса | Распределение трафика custom-весами |
| Авто-fallbacks | При сбое провайдера автоматически идёт следующий по весу |
Лучшие практики
allowed_models: ["*"] — разрешает все модели провайдера, валидация через каталог моделей (см. секцию выше).
allowed_models: [] (пустой массив) — отказывает всем моделям; ни один запрос для этой конфигурации не пройдёт.
Пустой provider_configs — все провайдеры заблокированы (deny-by-default). Чтобы пропустить трафик через виртуальный ключ, добавьте конфигурации провайдеров явно.
Адаптивная балансировка
Возможность Enterprise. Adaptive Load Balancing доступен в Enterprise-редакции Meridian. Подробнее: neria.cloud.
Адаптивная балансировка автоматически оптимизирует маршрутизацию по метрикам производительности в реальном времени. Работает на двух уровнях: macro-уровне (выбор провайдера) и micro-уровне (выбор ключа).
Двухуровневая архитектура
Разделение выбора провайдера (направления) и выбора ключа (маршрута) даёт:
- Оптимизацию на уровне провайдера — лучший провайдер для модели по агрегированной производительности;
- Оптимизацию на уровне ключа — внутри провайдера выбирается лучший API-ключ;
- Устойчивость — даже когда провайдер задан явно (governance или пользователем), оптимизация ключа продолжает работать.
Уровень 1: направление (выбор провайдера)
Когда выполняется: только когда строка модели не содержит префикс провайдера (например, gpt-4o).
Как:
- Поиск в каталоге — все настроенные провайдеры, поддерживающие модель.
- Фильтрация по:
- allowed_models из конфигурации ключей;
- доступности ключей у провайдера.
- Скоринг производительности:
- error rates (вес 50 %);
- latency (вес 20 %, алгоритм MV-TACOS);
- utilization (вес 5 %);
- momentum bias (ускорение восстановления).
- Smart selection: weighted random с jitter и exploration.
- Fallbacks: оставшиеся провайдеры сортируются по убыванию score.
Уровень 2: маршрут (выбор ключа)
Когда выполняется: всегда, даже если провайдер уже выбран (governance, пользователем или уровнем 1).
Как:
- Сбор ключей провайдера.
- Фильтрация по конфигурации (ограничения по моделям).
- Скоринг каждого ключа:
- error rates (недавние сбои);
- latency;
- TPM hits (нарушения rate limit);
- текущее состояние (
Healthy,Degraded,Failed,Recovering).
- Weighted random с exploration (25 % шанс «зондирования» recovering-ключа).
- Circuit breaker: ключи с весом 0 пропускаются (TPM hits, повторные сбои).
Алгоритм скоринга
Балансировщик считает score для каждой пары provider-model:
Score = (P_error × 0.5) + (P_latency × 0.2) + (P_util × 0.05) − M_momentumМеньшие штрафы → бо́льшие веса → больше трафика. Система самовосстанавливается: быстро штрафует проблемные маршруты и быстро возвращает их в работу после восстановления.
Поток запроса
Запрос без префикса провайдера:
curl -X POST http://localhost:8080/v1/chat/completions \
-d '{"model": "gpt-4o", "messages": [...]}'Поиск в каталоге. Поддерживают gpt-4o: [openai, azure, groq].
Оценка производительности:
- OpenAI: 0.92 (низкая latency, 99 % успехов);
- Azure: 0.85 (средняя latency, 98 % успехов);
- Groq: 0.65 (высокая latency недавно).
Выбор провайдера. OpenAI (наивысший score в jitter-диапазоне).
Преобразование запроса:
{
"model": "openai/gpt-4o",
"messages": [...],
"fallbacks": ["azure/gpt-4o", "groq/gpt-4o"]
}Возможности
| Возможность | Описание |
|---|---|
| Авто-оптимизация | Без ручного подбора весов |
| Real-time адаптация | Веса пересчитываются каждые 5 секунд |
| Circuit breakers | Падающие маршруты автоматически выводятся из ротации |
| Быстрое восстановление | Снижение штрафа на 90 % за 30 секунд после устранения |
| Health states | Healthy, Degraded, Failed, Recovering |
| Smart exploration | 25 % шанс «зондирования» восстановившихся маршрутов |
Видимость в дашборде
Мониторинг балансировки в реальном времени:
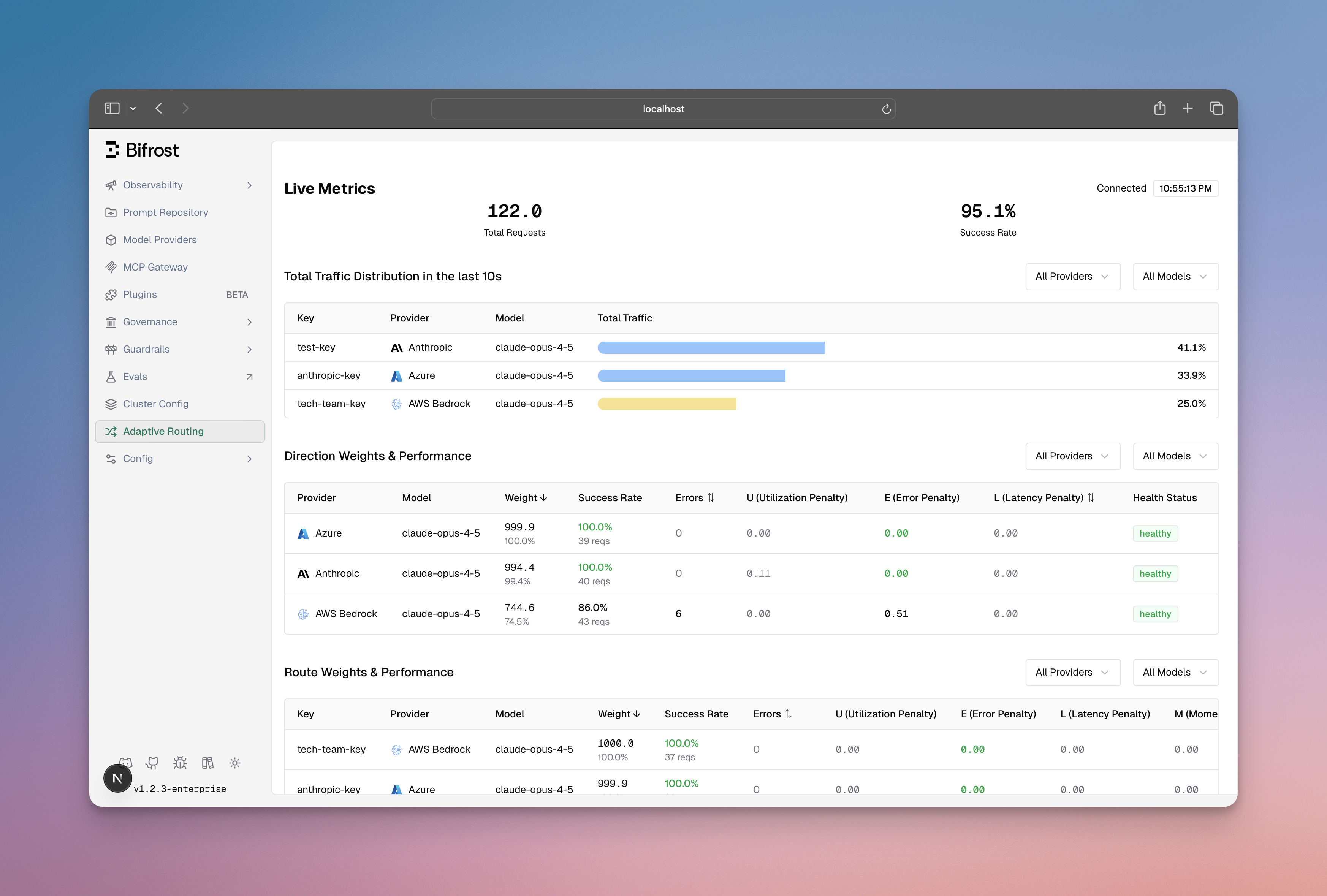
В дашборде отображается:
- распределение весов по маршрутам provider-model-key;
- метрики производительности (error rate, latency, success rate);
- переходы состояний (
Healthy → Degraded → Failed → Recovering); - фактическое vs ожидаемое распределение трафика.
Как governance и балансировка взаимодействуют
Когда оба механизма доступны, они работают согласованно по двум уровням.
Ключевая идея. У балансировки два уровня:
- Уровень 1 (направление / провайдер) — пропускается, если провайдер уже задан;
- Уровень 2 (маршрут / ключ) — всегда выполняется, даже если провайдер задан.
То есть оптимизация ключа работает независимо от того, кто выбрал провайдера.
Поток выполнения
Порядок выполнения
- HTTPTransportIntercept (governance, уровень провайдера) — выполняется первым; если у виртуального ключа есть
provider_configs, добавляет префикс провайдера. Результат: провайдер выбран governance. - Middleware (балансировка, уровень провайдера / направление) — после governance; если в строке модели уже есть
/, пропускает выбор провайдера; иначе делает performance-based выбор. Результат: префикс добавлен, если его не было. - KeySelector (балансировка, уровень ключа / маршрут) — всегда выполняется во время исполнения запроса в ядре Meridian: получает ключи провайдера, фильтрует по ограничениям модели, скорит и выбирает лучший. Результат: оптимальный ключ внутри выбранного провайдера.
Даже когда governance задал azure/gpt-4o, балансировка всё равно подбирает оптимальный ключ Azure по метрикам. В этом сила двухуровневой архитектуры.
Сценарии
Конфигурация:
- у виртуального ключа есть
provider_configs; - адаптивная балансировка выключена.
Запрос:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [...]}'Поведение:
- Governance делает weighted-провайдера → выбирает Azure (вес 0.7).
- Модель:
azure/gpt-4o. - Стандартный выбор ключа (не адаптивный) — по статическим весам.
- Запрос уходит в Azure с выбранным ключом.
Конфигурация:
- виртуальный ключ не передан (нет
x-bf-vk) — это и есть LB-only сценарий; - виртуальный ключ с пустым/отсутствующим
provider_configsблокирует все провайдеры (deny-by-default), и это не LB-only; - адаптивная балансировка включена.
Запрос:
curl -X POST http://localhost:8080/v1/chat/completions \
-d '{"model": "gpt-4o", "messages": [...]}'Поведение:
- LB уровня 1 делает performance-based выбор провайдера → OpenAI.
- Модель:
openai/gpt-4o. - LB уровня 2 выбирает лучший ключ OpenAI по метрикам.
- Запрос уходит в OpenAI с оптимальным ключом.
Конфигурация:
- у виртуального ключа есть
provider_configs; - адаптивная балансировка включена;
- у Azure три ключа:
azure-key-1,azure-key-2,azure-key-3.
Запрос:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [...]}'Поведение:
- Governance идёт первым (уважает явную настройку) → выбирает Azure.
- Модель:
azure/gpt-4o. - LB уровня 1 видит
/и пропускает выбор провайдера. - LB уровня 2 продолжает работать! Скорит ключи Azure:
azure-key-1: 99 % успехов, 150 мс latency → 0.95;azure-key-2: 85 % успехов, 200 мс latency → 0.60 (degraded);azure-key-3: TPM лимит → 0.0 (circuit broken);- выбран
azure-key-1.
- Запрос уходит в Azure с
azure-key-1.
Governance отвечает за провайдера (явное намерение пользователя), балансировка — за ключ (автоматическая оптимизация).
Конфигурация:
- governance и балансировка включены;
- у OpenAI два доступных ключа.
Запрос:
curl -X POST http://localhost:8080/v1/chat/completions \
-d '{"model": "openai/gpt-4o", "messages": [...]}'Поведение:
- Governance видит
/и пропускает. - LB уровня 1 видит
/и пропускает выбор провайдера. - LB уровня 2 работает: выбирает лучший ключ OpenAI по текущим метрикам.
- Запрос уходит в OpenAI с оптимальным ключом.
Пользователь явно указал провайдера, но оптимизация на уровне ключа всё равно полезна.
Правила выбора провайдера и ключа
| Сценарий | Выбор провайдера | Выбор ключа |
|---|---|---|
VK с provider_configs | Governance (weighted random) | Стандартный или адаптивный (если включён) |
VK без provider_configs + LB | Заблокировано (пусто = провайдеров нет) | — |
| Без VK + LB | LB уровня 1 (производительность) | LB уровня 2 (производительность) |
| Модель с префиксом провайдера + LB | Пропускается (уже задан) | LB уровня 2 ✅ |
| LB не включён | Governance, пользователь или каталог | Стандартный (статические веса) |
Ключевой момент.
- Выбор провайдера уважает иерархию: правила маршрутизации → governance → LB уровня 1 → ручное указание.
- Выбор ключа работает независимо и получает выгоду от балансировки даже когда провайдер предопределён.
Это разделение и делает двухуровневую архитектуру мощной.
Правила маршрутизации (динамические выражения)
Положение в pipeline. Правила маршрутизации выполняются до выбора провайдера в governance и могут переопределить его. Они оцениваются раньше адаптивной балансировки и позволяют динамически переопределять провайдера/модель по runtime-условиям: заголовкам, параметрам, метрикам потребления и организационной иерархии.
Кратко
Правила маршрутизации дают expression-based контроль через CEL. В отличие от governance (статические веса), правила оцениваются в момент запроса.
Когда выполняются
Как это работает
- Правила оцениваются первыми в порядке scope (VirtualKey → Team → Customer → Global).
- Если правило совпало: provider/model/fallbacks переопределяются, governance
provider_configsпропускается. - Если совпадений нет: работает governance (weighted random).
- LB уровня 1 пропускается, если провайдер уже определён (есть
/). - LB уровня 2 (выбор ключа) работает всегда.
Доступные CEL-переменные
// Контекст запроса
model // Запрошенная модель
provider // Текущий провайдер
// Заголовки и параметры (без учёта регистра)
headers["x-tier"] // Заголовок запроса
params["region"] // Query-параметр
// Контекст организации
virtual_key_id // ID виртуального ключа
team_name // Имя команды
customer_id // ID клиента
// Метрики потребления (0–100 %)
budget_used // Использование бюджета
tokens_used // Использование токенового rate limit
request // Использование request rate limitПримеры
По тарифу пользователя
headers["x-tier"] == "premium" // → openai/gpt-4oFallback при высоком бюджете
budget_used > 85 // → groq/llama-2 (дешевле)По команде
team_name == "ml-research" // → anthropic/claude-3-opusСложное многокритериальное
headers["x-environment"] == "production" &&
tokens_used < 75 &&
team_name == "ai-platform" // → openai/gpt-4oИерархия scope
Правила оцениваются по precedence (first-match-wins):
1. VirtualKey scope (наивысший)
2. Team scope
3. Customer scope
4. Global scope (низший)Внутри одного scope — по приоритету (по возрастанию: 0 раньше 10).
Возможности
| Возможность | Описание |
|---|---|
| CEL-выражения | Композиционный язык условий с богатым набором операторов |
| Иерархия scope | Правила на уровне VirtualKey/Team/Customer/Global с правильной precedence |
| Динамический override | Переопределение провайдера и/или модели по runtime-условиям |
| Fallback-цепочки | Несколько резервных провайдеров для авто-failover |
| Приоритеты | Меньше — раньше внутри одного scope |
| Capacity awareness | Доступ к real-time использованию бюджета и rate limits |
Подробная документация: Правила маршрутизации.
Как выбрать подход
-
Используйте governance, когда:
- ✅ требуется compliance (данные в определённом регионе/провайдере);
- ✅ нужен явный контроль над оптимизацией стоимости;
- ✅ нужны жёсткие лимиты бюджета на провайдера;
- ✅ разделение окружений (разные команды/приложения, разные провайдеры);
- ✅ управление rate limit'ами провайдеров.
-
Используйте правила маршрутизации, когда:
- ✅ нужна динамическая маршрутизация по runtime-контексту (заголовки, параметры);
- ✅ нужен capacity-aware routing (fallback при росте бюджета или rate limit);
- ✅ организационные правила (разные правила для команд/клиентов);
- ✅ A/B-тесты;
- ✅ сложные условия (тариф + capacity + команда).
-
Используйте балансировку, когда:
- ✅ нужна автоматическая оптимизация по производительности;
- ✅ хочется минимума настройки;
- ✅ нагрузки часто меняются;
- ✅ нужен мгновенный авто-failover;
- ✅ нужна устойчивость через multi-provider redundancy.
-
Используйте всё вместе, когда:
- ✅ нужно полное решение: governance задаёт базу, правила добавляют динамику, балансировка оптимизирует ключи;
- ✅ разные виртуальные ключи используют разные стратегии;
- ✅ enterprise-развёртывания со сложной структурой требований.