Маршрутизация
Направление запросов к конкретным моделям, провайдерам и API-ключам с помощью виртуальных ключей. Балансировка нагрузки по весам, автоматические fallback'и и тонкий контроль доступа.
Ищете полный обзор маршрутизации провайдеров?
Подробное руководство, охватывающее governance-маршрутизацию, адаптивную балансировку нагрузки, Model Catalog и их взаимодействие, см. на странице Маршрутизация провайдеров.
Эта страница посвящена настройке governance-маршрутизации именно через виртуальные ключи.
Обзор
Возможности governance-маршрутизации Meridian обеспечивают точечный контроль над тем, как запросы направляются к моделям и провайдерам, через конфигурацию виртуального ключа. Настраивая правила маршрутизации на VK, вы определяете, какие провайдеры и модели доступны, реализуете стратегии балансировки нагрузки по весам, создаёте автоматические fallback'и и ограничиваете доступ к конкретным API-ключам провайдера.
Это покрывает ключевые сценарии:
- Отказоустойчивость и failover — автоматический переход на резервного провайдера при сбое основного.
- Разделение окружений — выделенные виртуальные ключи под dev, test и production окружения с разным доступом к провайдерам и ключам.
- Управление расходами — направление трафика на более дешёвые модели или провайдеров по весам для оптимизации стоимости.
- Тонкий контроль доступа — гарантия того, что разные команды и приложения используют только те модели и API-ключи, которые им явно разрешены.
Ограничения по провайдерам и моделям
Виртуальные ключи можно ограничить только конкретными провайдерами и моделями. При настроенных ограничениях VK получает доступ только к указанным комбинациям provider/model, что даёт точечный контроль над тем, какие модели могут использовать разные пользователи и приложения.
Как это работает:
- Без provider configs (по умолчанию) — VK блокирует всех провайдеров (deny-by-default). Чтобы пропускать трафик, нужно добавить конфигурации провайдеров.
- С provider configs — VK ограничен только указанными provider/model. Настроенные провайдеры участвуют в балансировке по весам только при числовом значении
weight; провайдеры сweight: nullостаются настроенными, но не участвуют в выборе по весу.
Валидация модели:
Когда на VK настроены ограничения по провайдерам, Meridian проверяет, что запрошенная модель разрешена для выбранного провайдера:
allowed_models: ["*"]— разрешить все модели, поддерживаемые провайдером (валидация через Model Catalog).- Пустой
allowed_models— запретить всё (deny-by-default). - Явный список моделей — допускаются только эти модели.
- Синхронизация Model Catalog — на старте и при обновлении провайдера Meridian вызывает list models API каждого провайдера. При сбое появится предупреждение:
{"level":"warn","message":"failed to list models for provider <name>: failed to execute HTTP request to provider API"}.
Кросс-провайдерная маршрутизация автоматически НЕ происходит. Например, запросы к gpt-4o НЕ будут направляться на Anthropic, если вы явно не добавите "gpt-4o" в allowed_models Anthropic в конфигурации виртуального ключа. Каждый провайдер обрабатывает только те модели, которые он реально поддерживает (определяется Model Catalog).
Балансировка нагрузки по весам
Когда на виртуальном ключе настроено несколько провайдеров, Meridian автоматически реализует балансировку нагрузки по весам. Каждому провайдеру можно задать вес, и запросы распределяются пропорционально. Поле weight опционально — если его не указать (или задать null), провайдер исключается из выбора по весам, но остаётся доступным для прямых запросов вида provider/model и для использования как fallback.
Пример конфигурации:
Virtual Key: vk-prod-main
├── OpenAI
│ ├── Allowed Models: [gpt-4o, gpt-4o-mini] ← явный whitelist
│ └── Weight: 0.2 (20% трафика)
└── Azure
├── Allowed Models: [gpt-4o] ← явный whitelist
└── Weight: 0.8 (80% трафика)Поведение балансировки:
- Для
gpt-4o: 80% Azure, 20% OpenAI (модель есть вallowed_modelsобоих провайдеров). - Для
gpt-4o-mini: 100% OpenAI (модель есть вallowed_modelsтолько у OpenAI). - Для
claude-3-sonnet: запрос отклонён (нет ни у одного провайдера вallowed_models).
Использование:
Чтобы задействовать балансировку по весам, отправляйте запрос только с именем модели:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [{"role": "user", "content": "Hello!"}]}'Чтобы обойти балансировку и обратиться к конкретному провайдеру:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "openai/gpt-4o", "messages": [{"role": "user", "content": "Hello!"}]}'Веса автоматически нормализуются к сумме 1.0 на основе весов всех провайдеров, доступных на VK для запрошенной модели.
Пример с wildcard allowed_models (разрешить всё через Model Catalog):
{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["*"],
"weight": 0.5
},
{
"provider": "anthropic",
"allowed_models": ["*"],
"weight": 0.5
}
]
}С такой конфигурацией:
- Запрос
gpt-4o→ направлен в OpenAI (Model Catalog показывает поддержку). - Запрос
claude-3-sonnet→ направлен в Anthropic (Model Catalog показывает поддержку). - Запрос
gpt-4oНЕ направится в Anthropic (Model Catalog показывает, что Anthropic не поддерживает модели OpenAI).
Автоматические fallback'и
Когда на VK настроено несколько провайдеров, Meridian автоматически создаёт цепочки fallback для отказоустойчивости. Это даёт автоматический failover без ручной настройки.
Как это работает:
- Активируется только когда в теле запроса нет массива
fallbacks. - Создание fallback — провайдеры сортируются по весу (от большего к меньшему) и добавляются как fallback'и.
- Уважение существующих fallback'ов — если вы передали
fallbacksвручную, они сохраняются.
Пример потока запроса:
- Основной запрос идёт к провайдеру, выбранному по весу (например, Azure с весом 80%).
- Если Azure упал — автоматический повтор на OpenAI.
- Так до успеха или пока не закончатся провайдеры.
Запрос с автоматическими fallback'ами:
# Этот запрос получит автоматические fallback'и
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [{"role": "user", "content": "Hello!"}]}'Запрос с ручными fallback'ами (автоматические не добавляются):
# Этот запрос сохраняет указанные вами fallback'и
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{
"model": "gpt-4o",
"messages": [{"role": "user", "content": "Hello!"}],
"fallbacks": ["anthropic/claude-3-sonnet-20240229"]
}'Настройка маршрутизации по провайдерам и моделям
- Перейдите в Virtual Keys.
- Создайте или отредактируйте виртуальный ключ.
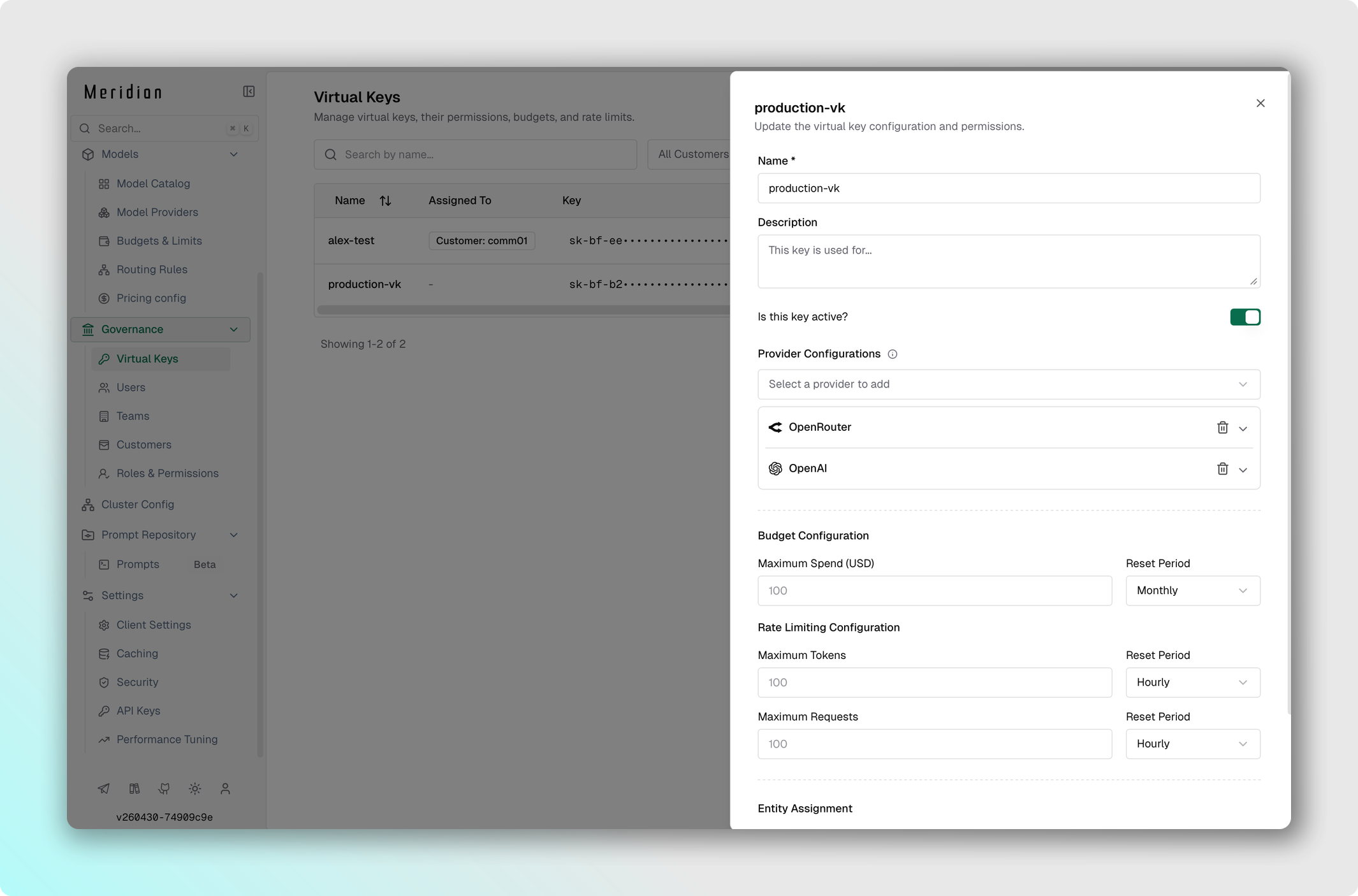
- В разделе Provider Configurations добавьте провайдера, к которому хотите ограничить VK.
- Allowed Models:
- Конкретные модели — задайте список (например,
["gpt-4o", "gpt-4o-mini"]), чтобы явно разрешить только их; ["*"]— разрешить все модели (валидация через Model Catalog);- Оставить пустым — запретить все модели (deny-by-default).
- Конкретные модели — задайте список (например,
- При необходимости задайте вес для провайдера (числовое значение для балансировки по весам или оставьте пустым, чтобы исключить из взвешенной маршрутизации, оставив провайдера доступным для прямых запросов и fallback'ов).
- Нажмите Save.
curl -X PUT http://localhost:8080/api/governance/virtual-keys/{vk_id} \
-H "Content-Type: application/json" \
-d '{
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o", "gpt-4o-mini"],
"weight": 0.2
},
{
"provider": "azure",
"allowed_models": ["gpt-4o"],
"weight": 0.8
}
]
}'{
"governance": {
"virtual_keys": [
{
"id": "vk-prod-main",
"provider_configs": [
{
"provider": "openai",
"allowed_models": ["gpt-4o", "gpt-4o-mini"],
"weight": 0.2
},
{
"provider": "azure",
"allowed_models": ["gpt-4o"],
"weight": 0.8
}
]
}
]
}
}Ограничения по API-ключам
Виртуальные ключи можно ограничить конкретными API-ключами провайдера. С такими ограничениями VK получает доступ только к указанным ключам, что даёт точечный контроль над тем, какие API-ключи доступны разным пользователям и приложениям.
Как это работает:
- Без ограничений (
key_ids: ["*"]) — VK может использовать любые доступные ключи провайдера в рамках балансировки. - С ограничениями — VK ограничен только указанными ID ключей, остальные доступные ключи игнорируются.
- Полный запрет (
key_ids: []или поле отсутствует) — VK не может использовать ни один ключ провайдера (deny-by-default).
Пример сценария:
Доступные ключи провайдера:
├── key-prod-001 → sk-prod-key... (production-ключ OpenAI)
├── key-dev-002 → sk-dev-key... (dev-ключ OpenAI)
└── key-test-003 → sk-test-key... (test-ключ OpenAI)
Ограничения виртуальных ключей:
├── vk-prod-main
│ ├── Allowed Models: [gpt-4o]
│ └── Restricted Keys: [key-prod-001] ← ТОЛЬКО production-ключ
├── vk-dev-main
│ ├── Allowed Models: [gpt-4o-mini]
│ └── Restricted Keys: [key-dev-002, key-test-003] ← dev + test
└── vk-unrestricted
├── Allowed Models: ["*"] ← все модели через каталог
└── Restricted Keys: ["*"] ← можно ЛЮБОЙ доступный ключПоведение запросов:
# Production VK — будет использован ТОЛЬКО key-prod-001
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-prod-main" \
-d '{"model": "gpt-4o", "messages": [{"role": "user", "content": "Hello!"}]}'
# Dev VK — балансировка между key-dev-002 и key-test-003
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-dev-main" \
-d '{"model": "gpt-4o-mini", "messages": [{"role": "user", "content": "Hello!"}]}'
# VK с key_ids: ["*"] — может использовать любой доступный ключ OpenAI
curl -X POST http://localhost:8080/v1/chat/completions \
-H "x-bf-vk: vk-unrestricted" \
-d '{"model": "gpt-4o-mini", "messages": [{"role": "user", "content": "Hello!"}]}'Настройка ограничений по API-ключам:
- Перейдите в Virtual Keys.
- Создайте или отредактируйте виртуальный ключ.
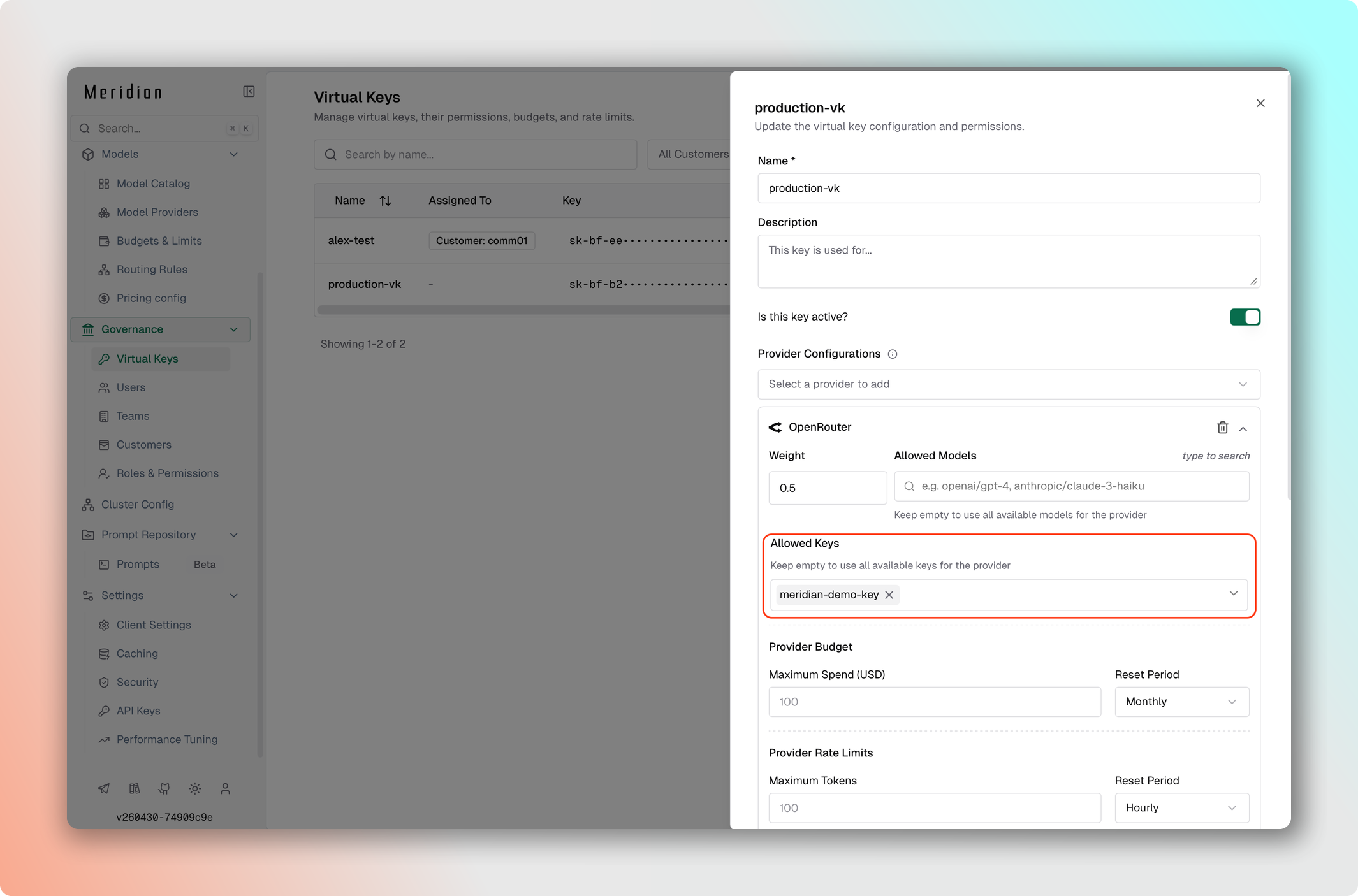
- В разделе Allowed Keys выберите API-ключи, к которым хотите ограничить VK.
- Нажмите Save.
curl -X PUT http://localhost:8080/api/governance/virtual-keys/{vk_id} \
-H "Content-Type: application/json" \
-d '{
"key_ids": ["key-prod-001"]
}'{
"governance": {
"virtual_keys": [
{
"id": "vk-prod-main",
"provider_configs": [
{
"provider": "openai",
"key_ids": [
"key-prod-001"
]
}
]
}
]
}
}Сценарии использования:
- Разделение окружений — production VK работают с production-ключами, dev VK — с dev-ключами;
- Контроль расходов — разные команды используют ключи на разных биллинговых аккаунтах;
- Контроль доступа — чувствительные ключи доступны только определённым VK;
- Compliance — гарантия того, что отдельные нагрузки используют только compliant/audited ключи.
Ограничения моделей, заданные на отдельных ключах провайдера, всегда применяются в дополнение к ограничениям provider/model и API-ключей, заданным на виртуальном ключе.
Диагностика
Сбои синхронизации Model Catalog
Если в логах Meridian при старте или обновлении провайдера появляются предупреждения вида:
{"level":"warn","time":"2026-01-13T14:18:53+05:30","message":"failed to list models for provider ollama: failed to execute HTTP request to provider API"}Что это значит:
- Meridian попытался вызвать list models API провайдера, чтобы наполнить Model Catalog.
- Запрос не прошёл (сетевая проблема, недоступность провайдера, неверные креденшелы и т. д.).
- Если у виртуального ключа для этого провайдера задано
allowed_models: [](пустой), все модели будут запрещены. Используйте["*"], чтобы разрешить все модели.
Как починить:
- Проверьте, что провайдер корректно настроен и доступен.
- Проверьте сетевую доступность API провайдера.
- Убедитесь, что креденшелы валидны.
- Используйте
allowed_models: ["*"], чтобы разрешить все модели, или задайте явный список для критически важных провайдеров.
Виртуальные ключи
Виртуальные ключи (Virtual Keys) — основная сущность governance в Meridian. Они дают пользователям и приложениям ограниченный доступ к моделям и провайдерам, а также бюджеты и rate limits.
Бюджеты и лимиты
Enterprise-уровень управления бюджетами и контроля расходов с иерархическим распределением через виртуальные ключи, команды и клиентов.